国内外专利挖掘研究进展综述
摘 要 [目的/意义]专利挖掘是获取技术情报的重要途径,在近年来智能技术快速发展的驱动下,专利挖掘不仅在方法自动化、智能化和挖掘深度、精确度上取得了长足进步,而且展露出数据与算法紧密融合的发展新范式,亟需通过综述形成对其研究现状和发展趋势的全面认识。[方法/过程]将文献调研活动的主要环节连成闭环“检索->筛选->梳理->查漏->拓展和再次检索”并持续更新、反复迭代,调研范围包括国内外专利挖掘的相关论文、专利、数据集、算法竞赛评测活动、专利信息服务平台乃至代码托管网站和模型托管网站,并在叙述内容中穿插了专家访谈、竞赛选手交流会以及笔者学术成果评审意见中获得的相关信息,最终完成对专利挖掘的系统综述。[结果/结论]专利基础资源的种类和数量较之前增长较快,专利挖掘方法的训练和性能评测逐步具有数据基准和统一测度标准;专利挖掘前沿方法紧跟智能技术发展步伐以实现技术升级和性能提升,而统计学习、人工规则、软件工具等传统方法也在学习成本、实践成本和方法效果的平衡中得到了优化和发展;专利挖掘的研究范围实现了从数据处理、规范化到专利基础服务和技术情报分析的全面覆盖,并开启了专利智慧法律的探索。
1 引言
专利是一项社会契约,它通过公开一项发明的技术内容,换取发明拥有者在有限时间段内对该项发明的完全专有权,从而在保障创新者权益、激励创新行为的同时,推动该项发明的社会效益在专利期满后得到广泛传播(LEVIN R C,1986)。相比其他科技信息,专利具有题录丰富、内详尽、格式规范、分类科学、时效性强、覆盖面广等优点,据统计,专利覆盖了世界上最新技术信息的90%,其中80%的技术信息不会以其他形式发布(ZHA X& CHEN M, 2010)。专利挖掘是从专利数据中获取技术情报的重要方式,该概念起源自A. Porter与S. Cunningham(2004)所提的技术挖掘(tech mining),即利用文本挖掘技术从科学、技术和创新(ST& I)信息记录集合中获取技术情报,当将技术挖掘目标限定到专利分析时,就是专利挖掘。随着智能信息技术的快速发展和情报分析方法的长足进步,专利挖掘的内涵和外延也在不断深化和拓展,为跟踪这些变化,胡正银等(2014)、屈鹏等(2014)、L. Zhang等(2015)分别于2014—2015年连续撰文对专利挖掘研究进展进行综述。其中胡正银等延续A. Porter与 S. Cunningham的定义,从文本挖掘角度汇总相关成果,屈鹏等将专利挖掘的研究范围拓展到文本挖掘和数据挖掘,L. Zhang等更是进一步整理了专利挖掘的定义,即利用机器学习、自然语言处理、机器翻译、信息检索、信息可视化等技术手段,来协助专利分析人员进行专利文献调研、处理和深入分析,进而支持一系列重要的技术情报任务,这也成为本文所秉承的专利挖掘定义。近年来有国内知识产权从业者使用“专利挖掘”来表达专利申请者“有意识地对创新成果进行创造性的剖析和甄选,进而从最合理的权利保护角度确定用以申请专利的技术创新点和技术方案的过程”(马天旗, 赵强, 苏丹等, 2020),但该定义无论实现手段还是达成目标都与前述定义相去甚远,故不在本文探讨范围之内。
经过20年的发展,专利挖掘已经形成了较大的方法家族,但从其具体内容来看,这些方法更多是各项信息技术在不同专利场景上的应用研究,不成体系且缺乏理论指导。虽然胡正银等、屈鹏等、L. Zhang等从各自角度对这一领域的研究成果进行了梳理和总结,并指出未来的挑战存在于如何建立能够准确揭示技术发明关键信息的专利内容表示方法,如何让智能算法充分利用专利数据特点,更加全面、精准地完成专利挖掘任务,如何将专利与产品、诉讼等其他信息相结合,使专利挖掘的技术边界触达专利实务的核心问题,如专利侵权分析、专利新颖性识别等,以及应对所有这些挑战的前提——如何推动学术社区在统一训练数据和评测标准下开展专利挖掘研究,以便不同技术方案之间的横向对比并产生可复现、可信赖的评测结果,让真正优秀的研究成果脱颖而出。但这些综述距今时隔已久,经历了近年来大数据和人工智能的长足发展后,先前作为专利挖掘技术基础的统计机器学习逐步显现出被深度神经网络、预训练模型乃至大语言模型替代的趋势。而在新形势下算法和数据结合的密切程度前未所有,这不仅体现在高质量数据基准(benchmark)带来智能计算技术跨越式发展的案例屡见不鲜,更体现在研究者在海量语料和微调指令上训练、微调预训练模型和大语言模型,并将所产生的词嵌入向量和检查点(checkpoint)文件分享出来供后续学者直接加载和重复使用。因此当再次对专利挖掘展开综述时,除全面梳理国内外专利挖掘技术的最新进展外,本文也对专利公开数据和模型文件现状展开综述,从而在数据、算法密切结合的智能技术研究新范式下帮助读者建立对专利挖掘研究现状和未来发展趋势的全面认识。
2 文献材料获取和内容综述方法简介
本文对近年来专利挖掘领域出现的技术方法、标注数据乃至预训练模型、大语言模型所产生的词向量词典、模型检查点文件进行了全面调研,文献材料来源如表1所示:
表1 文献材料来源汇总
Table 1 Summary of sources for documents and other resources
| 来源类型 | 来源名称 | 网址 |
|---|---|---|
| 论文数据库 | 科睿唯安科学网 | https://www.webofscience.com |
| 谷歌学术检索 | https://scholar.google.com | |
| 万方数据知识服务平台 | https://www.wanfangdata.com.cn/ | |
| 计算机科学文献库 | https://dblp.org/ | |
| 美国计算机学会数据库 | https://dl.acm.org | |
| 在线科学预印本存储库 | https://arxiv.org/ | |
| 专利数据库 | 智慧芽专利数据库 | https://www.zhihuiya.com/ |
| 代码托管网站 | Github | https://github.com |
| 模型托管网站 | Huggingface | https://huggingface.co/ |
由于调研对象类型繁多、内容庞杂,采用构造检索式、文献检索筛选、阅读汇总这种惯常的文献调研方法容易失之偏颇、挂一漏万,因此本文将上述环节连成闭环持续更新、反复迭代,并在该过程中融合了调研文献的前向引用和后向引用,文献数据库平台提供的推荐文章列表,专家访谈、数据竞赛选手交流会以及笔者撰写论文、专著、申请项目的评审意见所提供的文献、数据等,最终完成对专利挖掘的系统综述。按照专利信息服务中的数据流转顺序,本文将这些调研材料划分为基础资源建设、数据处理和规范化以及面向专利信息服务的智能算法研究3个模块,具体如图1所示:

图1 专利挖掘研究成果汇总
Figure 1 Summary of research achievements in patent mining field
其中基础资源建设既包括构建无标注或标注数据集来为智能算法的训练提供原材料,也包括创建词向量文件和模型检查点文件为后继研究者提供模型基础;数据处理和规范化指从专利文献中抽取关键信息并对其加以规范整合和结构化,以消除专利中固有的模糊性和二义性,并使其中的技术核心要素凸显出来,来支撑上层专利应用服务;面向专利应用服务的智能方法研究以前两个模块为基础来构建算法模型,为终端用户的实际需求提供解决方案。
本文其余部分安排如下:第三节对基础资源建设情况进行汇总梳理,第四节对数据处理和规范化方法相关成果进行阐述,第五节为面向专利信息服务的智能算法研究,最后在总结当前专利挖掘研究不足和挑战的基础上,对可能的解决之道和未来发展前景进行探讨。值得注意的是,专利挖掘横跨人工智能和知识产权两大领域,尤其方法研究部分更是纷繁庞杂、水平不一,因此在第四、五节选取其中代表性较强的研究方向重点介绍。
3. 基础资源建设
相比其他科技文献,专利原始数据的获取非常便利,例如美国专利商标局以API接口形式提供了最新专利数据的官方下载通道(详见https://developer.uspto.gov/data),欧洲专利局提供1978年以来专利申请和授权全文的批量下载(详见https://www.epo.org/searching-for-patents/data/bulk-data-sets/data.html)。这为基础资源建设提供了得天独厚的优势。丰富的字段信息使得专利原始数据具有标注和无标注数据的双重属性:专利的技术分类标签,以及不同国家专利局之间用于数据交换的多语种专利文本,使得专利文献是天然的类别标注数据集和平行语料库;但对于其他专利挖掘任务,如命名实体识别、语义关系抽取来说,专利则是无标注数据,需要人工标注后才能训练相关模型。为避免混淆,在本文中将标注特指为在专利原始数据基础上继续展开的人工标注活动,而将人工标注后的专利数据称为标注数据资源、将专利原始数据称为无标注数据资源。
3.1 无标注数据资源
受益于专利数据本身丰富的字段信息及其易获取性,将专利原始数据转化为规范化数据资源的过程相对简单、自动化程度较高,这也使得此类数据集数量较多且每个数据集通常体量较大,例如美国国家经济研究局(National Bureau of Economic Research,NBER)发布的NBER数据集中包含约300万条专利题录信息和1 600万条专利引文信息(HALL B H, JAFFE A B, TRAJTENBERG M),美国专利商标局最新版专利审查研究数据集PatEx中包含了超过1 250万份公开的临时和非临时专利申请以及超过100万份专利合作条约(PCT)申请的详细信息(RICHARD M, 2021),更多数据资源详见表2。由于专利本身包含丰富的题录字段,即便未对这些数据资源做进一步的人工标注,它们也可以作为类别标注数据集、平行语料库、自动摘要数据集来支持专利分类、专利翻译、专利自动生成摘要等任务;不仅如此,还有无标注数据甚至可以支持专利文本的重写,比如为避免专利原文内容晦涩给用户带来理解障碍,德温特创新索引(Derwent innovations index)的结构化摘要系由领域专家对原始专利摘要改写而成,这些摘要信息可以和专利原文摘要以及权利要求项、专利说明书等字段相结合形成微调指令,帮助大语言模型(如GPT-2)学习如何提升专利文本的可读性(TRAPPEY A J C, TRAPPEY C V, WU J L, et al, 2020)。
表2 无标注数据资源汇总
Table 2 Summary of unlabeled data resources
| 数据集名称 | 数据来源 | 数据集内容 | 数据集规模及语种 |
|---|---|---|---|
| NBER dataset(HALL B H, JAFFE A B, TRAJTENBERG M) | 美国专利商标局 | 专利题录和引文数据 | 300万条专利题录,英文;1 600万条专利引文 |
| PatEx2021(RICHARD M, 2021) | 美国专利商标局 | 专利申请题录数据、审查员ID及其审查小组、专利交易历史数据 | 超过1 250万份专利申请记录和超过100万份PCT专利申请记录,英文 |
| USPTO-2M(USPTO-a) | 美国专利商标局 | 专利题录数据 | 200万条专利记录,英文 |
| 发明专利数据V2(北京大学开放研究数据平台) | 中国国家知识产权局 | 专利题录数据 | 277万条专利记录,中文 |
| NTCIR-7 PATMT(NTCIR-a) | 美国专利商标局和日本专利局 | 专利题录和全文数据 | 130万条美国专利记录,英文;350万条日本专利记录,日文 |
| NTCIR-8 PATMT(NTCIR-b) | 美国专利商标局和日本专利局 | 专利题录和全文数据 | 210万条美国专利记录,英文;525万条日本专利记录,日文 |
| BigPatent(SHARMA E, LI C, WANG L, 2019) | 美国专利商标局 | 专利全文 | 130万件专利,英文 |
| MAREC(Vienna University of Technology) | 欧洲专利局、世界知识产权组织、美国专利商标局、日本专利局 | 专利题录和部分全文数据 | 1 900万条专利记录,将近一半专利具有全文数据,语种以英语、德语、法语为主 |
| PTAB(USPTO-b) | 美国专利商标局 | 专利诉讼卷宗 | 截止2023年11月28日共16.5万条记录,目前还在更新中,英语 |
3.2 标注数据资源
依据J. Zhu等(2018)定义,标注是对未处理的初级数据, 包括语音、图片、文本、视频等进行加工处理, 并转换为机器可识别信息的过程。数据标注是大量人工智能算法得以有效运行的关键环节,数据标注越准确、标注的数据量越大,算法的性能就越好(蔡莉, 王淑婷, 刘俊晖, 等, 2020)。当前专利挖掘领域的数据标注工作主要面向专利检索、信息抽取以及其他任务展开,相关数据资源如表3所示:
表3 标注数据资源汇总
Table 3 Summary of labeled data resources
| 任务大类 | 任务类别细分 | 数据资源名称 |
|---|---|---|
| 专利检索 | 一般专利检索 | NTCIR-3 PATENT((NTCIR Project test collections - DATA)) |
| 篇章级专利有效性检索 | NTCIR-4 PATENT(NTCIR Project test collections - DATA)、NTCIR-5 PATENT(NTCIR Project test collections - DATA)、CLEF-IP-2009(CLEF-IP 2009 Download area)、CLEF-IP-2010(CLEF-IP 2009 Download area) | |
| 段落级专利有效性检索 | NTCIR-5 PATENT(NTCIR Project test collections - DATA)、CLEF-IP-2012(CLEF-IP 2012 Download area) | |
| 跨语种专利检索 | CLEF-IP-2009(CLEF-IP 2009 Download area)、CLEF-IP-2010(CLEF-IP 2010 Download area) | |
| 基于图片的专利有效性检索 | CLEF-IP-2011(CLEF-IP 2011 Download area) | |
| 在先技术和技术现状检索 | TREC-CHEM-2009(GOBEILL J, TEODORO D, PASCHE E, et al, 2009)、TREC-CHEM-2010(LUPU M, TAIT J, HUANG J, et al, 2010)、TREC-CHEM-2011(LUPU M, ZHAO J, HUANG J, et al, 2011) | |
| 专利信息抽取 | 命名实体识别 | NTCIR-8 PATMN(NTCIR-c)、THF-2020(CHEN L, XU S, ZHU L, et al., 2020)、CHEMDNER-patents(Track 2- CHEMDNER-patents)、CPC-2014(AKHONDI S A, KLENNER A G, TYRCHAN C, et al, 2014)、ChEMU 2020(HE J,NGUYEN D Q,AKHONDI S A, et al., 2020)、ChEMU 2022(LI Y, FANG B, HE J, et al., 2022) |
| 语义关系抽取 | THF-2020(CHEN L, XU S, ZHU L, et al., 2020)、ChEMU 2022(LI Y, FANG B, HE J, et al., 2022) | |
| 事件抽取 | ChEMU 2020(HE J,NGUYEN D Q,AKHONDI S A, et al., 2020)、ChEMU 2022(LI Y, FANG B, HE J, et al., 2022) | |
| 专利插图的化学结构、处理流程抽取 | CLEF-IP-2012(CLEF-IP 2012 Download area)、CLEF-IP-2013(CLEF-IP 2013 download area)、TREC-CHEM-2011(LUPU M, ZHAO J, HUANG J, et al, 2011) | |
| 其他 | 专利文本和插图之间的跨模态实体链接 | CLEF-IP-2013(CLEF-IP 2013 download area) |
| 专利术语匹配 | PhraseMatching(ASLANYAN G, Wetherbee I, 2022) | |
| 专利图片分类 | CLEF-IP-2011(CLEF-IP 2011 Download area) | |
| 专利诉讼 | PatentMatch(RISCH J, ALDER N, HEWEL C, et al, 2020) | |
| 医学研究 | Cancer Moonshot Patent Data(FRUMKIN J,MYERS A, 2016) |
由于专利检索本身在行业中的重要地位以及专利检索多样性(例如可专利性检索、有效性检索、侵权检索、确权检索、现有技术状况检索、专利全景检索等(HUNT, D, NGUYEN, L, RODGERS, M, 2012)所带来较高的研究价值,专利检索标注资源构建一直是信息检索和专利分析领域的重要工作内容。自2011年起,NTCIR(NTCIR-d)、CLEF(CLEF-Initiative-a)、TREC-CHEM(LUPU M, HUANG J, ZHU J, et al, 2009)、SIGIR先后举办了15次技术评测,并形成多种类型的专利检索标注数据集,内容涉及普通专利检索、篇章级专利有效性检索、段落级专利有效性检索、跨语种专利检索、基于图片检索的专利有效性检索以及在先技术检索和现有技术状况检索。这些数据资源一般以专利参考文献作为检索任务的目标文献,并辅以人工标注、清洗和审核工作,实现大规模标注数据资源的构建。一般来说每条专利标注数据包含3部分内容,即检索式(或检索主题)、专利文献编号以及对应的相关性等级标签。
信息抽取旨在解决一个长期困扰专利分析的基础问题,即如何高效、准确地从海量专利数据中识别技术及其属性、功能、效果、相关产品等,并实现这些信息之间的语义关联和规范化。由于专利文献中信息抽取标注可以借力的内容极少,该类资源建设所需人工劳动高度密集。但即便如此,也涌现出不少相关数据资源,内容涵盖命名实体识别、语义关系抽取、事件抽取乃至专利插图中的化学结构和处理流程识别等;同时专利信息提供商也从专利行业需求出发,将专利文献中高价值的技术要素提炼出来,例如科睿唯安的德温特专利创新索引将专利新颖性、先进性和用途抽取出来并作为改写后摘要的组成部分,智慧芽专利数据库也对专利要解决的技术问题及其功能效果进行了标注。
本文也发现专利标注数据资源建设在信息类型上向跨模态方式拓展,在研究目标上向智慧法律方向迈进。早在2011年,CLEF-IP-2011(CLEF-Initiative-b)就将专利图片划分为9种类型,包括摘要图、流程图、基因序列、符号、程序列表等,并形成包含38 087张图片的训练集和1 000张图片的测试集;2013年,CLEF-IP-2013(CLEF-Initiative-c)进一步举办了旨在关联文本和插图之间语义信息的跨模态实体链接测评;2022年,谷歌以合作专利分类号(cooperative patent classification)作为专利术语的语境信息,发布了包含约5万个术语对的专利术语匹配数据集PhraseMatching(ASLANYAN G, Wetherbee I, 2022),为跨语境术语语义匹配研究奠定了必要基础,德国波茨坦大学J. Risch等(RISCH J, ALDER N, HEWEL C, et al, 2020)更是在欧洲专利局提供的专利申请文件、公开文件和专利检索报告中萃取600万条句子级别的专利无效记录,并形成专利诉讼数据集PatentMatch供并形成专利诉讼数据集PatentMatch供开展智慧法律研究使用使用。
3.3 词嵌入向量词典和模型检查点
词嵌入向量词典和模型检查点是两种不同于专利文献数据的新型数据资源,是应用深度神经网络、预训练模型乃至大语言模型开展专利挖掘的基础条件。其中词嵌入向量词典由深度神经网络在语料库上运行产生,用于将用户输入的词汇或句子转化为向量或矩阵,从而为深度学习模型提供可执行的输入信息,模型检查点则是预训练模型或大语言模型预训练或微调完毕后存储下来的模型快照。由于创建这两类资源尤其是模型检查点对训练语料的体量和计算资源的规格要求不菲,当前主流范式是由技术能力较强、数据与算力充沛的企业或高校训练这两类资源并公开发布到模型托管网站,如Huggingface、魔搭社区(https://modelscope.cn),其他研究者和普通用户只需要将这些资源下载本地并加载起来,就可以实现词嵌入向量词典、预训练模型以及大语言模型的本地运行,从而避免重复训练所带来的资源浪费。对于专利挖掘来说,虽然这些模型托管网站提供了诸多基于通用语料库,如谷歌新闻数据集(MIKOLOV T, SUTSKEVER I, CHEN K, et al, 2013)、维基百科或网页数据集common crawl(https://commoncrawl.org/)所训练的词嵌入向量提供开放下载,然而J. Risch等(2019)发现,由于专利在句法结构和表达内容上显著迥异于通用语料,基于通用语料和专利语料训练的词嵌入向量在专利挖掘任务表现上差异明显,因此他们在USPTO-5M的540万美国专利全文数据上(目前该数据集下载链接已经被官方取消)上使用fastTEXT算法训练出100维、200维、300维共3种向量长度的词嵌入向量词典并提供公开下载(https://hpi.de/naumann/projects/web-science/paar-patent-analysis-and-retrieval/patent-classification.html),其中300维词嵌入向量在专利分类任务上的平准准确率较同样维度的通用词嵌入向量提升了17%。
预训练模型和大语言模型的专利挖掘性能同样会受到通用训练语料和专利挖掘任务之间领域不匹配的影响。有两种策略可以缓解甚至消除这一影响,其一是继承原有通用模型的词表和参数权重,但使用专利语料继续训练,以增加模型的领域适应性;其二是丢弃原有通用模型的词表和参数权重,利用专利语料重新构建词表并从头训练模型。第一种策略适合专利语料有限、不足以充分训练模型的情况,这种条件下两阶段混合训练策略往往能取得更好的效果。谷歌公司采用第二种策略,它从美国及其他国家采集超过1亿份专利文献的全文(包括摘要、权利要求项和说明书字段)并训练出可供开放下载的BERT-for-Patents(Google),在陈亮,张吉玉,刘一畅等(2022)参加2022年中国计算机学会大数据与计算智能大赛专利分类赛题的方案尝试中,谷歌公司的模型较通用版本BERT在专利分类效果上提升了8%(使用weighted-average F1指标评价),显示出强大的性能。同样使用第二种策略,J. S. Lee[49]基于1976年至2021年间共计731G专利全文数据,在GPT-3的开源替代大语言模型GPT-J-6B上配置和重新训练,最终形成参数量为60亿、16亿、4.56亿、2.79亿、1.91亿、1.28亿、1.15亿的7个模型检查点,其中最大4个模型检查点已经上传Huggingface网站并提供公开下载(下载链接https://huggingface.co/patent)。
3.4 小结
当前专利挖掘领域建设的基础资源类型较多、分布广泛,一方面由于专利自身丰富的题录和全文信息,外加各大专利局在专利业务和数据资源上的多年积累,使得从中衍生出的无标注数据资源,以及可以从专利原始数据中借力产生的标注数据资源数量较多、规模庞大;但另一方面,对于完全依赖人工标注建设的标注数据资源来说,还存在诸多问题,比如数据资源数量不足、规模也远逊于通用领域的相应数据资源,且存在领域偏好问题,即相当数量的标注数据出现在信息资源建设较为完备的生物、医学领域,而在同属技术前沿的电子、信息、智能制造等领域中标注数据却非常匮乏,而专利数据显著的领域依赖(domain-dependent)特点,即不同技术领域的标注数据难以跨领域使用,使得这些问题更加严峻。当然,也有值得欣喜的一面:基础资源建设的目标逐步从辅助数据处理、支持专利分类等常规业务迈向攻关专利信息服务核心难题,如跨语境术语匹配和专利无效宣告判定,同时研究者们也紧跟智能技术前沿步伐,积极投入预训练和大语言模型的数据资源建设,为全面升级专利挖掘的研究和应用提供必要基础。
4 专利信息处理和规范化
专利信息处理和规范化一直是传统专利数据加工建设的核心业务,在专利挖掘范畴下,其研究内容被从常规流程性工作中抽离出来,聚焦于从专利题录、文本中抽取关键信息并将其规范化、结构化以消除专利数据中存在的模糊性和歧义性,为计算机理解专利内容并支持上层的专利应用服务奠定基础。由于专利信息处理和规范化技术细节较多、内容涵盖较为广泛,本文选择其中代表性较强的术语抽取、命名实体识别、语义关系抽取、跨篇章共指消解等方向展开陈述。
4.1 术语抽取
术语是对特定科学技术概念的文字表述,可以是词或者词组,而术语抽取即使用计算机方法将术语从文本中提取出来并捕获其内在含义 。自上世纪80年代出现术语自动识别系统以来(VIVALDI J, CABRERA-DIEGO L A, SIERRA G, et al),大量学者对术语相关领域展开了广泛的研究,形成了成员众多的术语抽取方法家族,如表4所示:
表4 术语抽取方法分类(张雪, 孙宏宇, 辛东兴,等, 2020)
Table 4 Categories of terminology extraction methods
| 术语抽取方法分类 | 详细类别 | 内容 |
|---|---|---|
| 基础语言信息类 | 基于语言学的方法 | 词形特征,语义特征,词法特征 |
| 基于统计学的方法 | 词频特征 | |
| 混合方法 | 语义特征,词法特征,词频特征,等等 | |
| 基于外部知识的方法 | 候选词在特定领域与其在通用领域的对比特征 | |
| 基于机器学习的方法 | 语义特征,词法特征,词频特征,外部资源特征,分布式特征,等等 | |
| 基于深度学习的方法 | 分布式特征 | |
| 关系结构信息类 | 基于语义相关的方法 | 候选词之间的相似性 |
| 基于图的方法 | 候选词之间的关系特征:共现关系、语义相似,等等 | |
| 基于主题模型的方法 | 候选词在主题上的分布特征 |
较早出现的术语抽取方法包括基于语言学的方法、基于统计学的方法以及混合方法。基于语言学的方法利用句法解析软件从专利文本中获取词性、句法依存关系等特征,并在此基础上制定相关规则以获取术语,例如S. Dewulf(2011)认为专利文本中动词表示功能型术语而形容词表示属性型术语;J. Yoon等(2012)将这些规则进一步细化为“动词+名词”表示功能型术语,而“形容词+名词”表示属性型术语,同时他们使用了5种Stanford CoreNLP所定义的句法依存关系类型,并将其所关联词汇的词性拼装起来以识别术语。相比传统专利分析中所使用的题录数据,这些从专利文本中识别出来的术语包含着专利的原理、组成、功能效果、新颖性、先进性等核心内容,因此可以更好反映出行业创新方向(DEWULF S, 2011)、技术发展趋势(YOON J, KIM K, 2012)以及可能的技术机会(YOON J, KO N, KIM J, 2015)。
然而使用常规语料训练出的句法解析器在专利这种长句、难句俯拾皆是的文本上面临着处理速度和准确率同时跌落的事实,同时专利文本典型的领域依赖属性使得人工规则的可移植性较差。对此,研究者提出了基于统计学的术语抽取方法以及两者的混合方法,如D. A. Evans和R. G. Lefferts(EVANS D A, LEFFERTS R G, 1995)利用TF-IDF进行术语抽取;K. Frantzi等(2000)在词性组合规则的基础上,利用术语及其内嵌子术语的统计学特征,提出了C-value方法;不仅如此,他们注意到术语与其上下文环境的密切关系,进一步提出了将候选术语的C-value得分与其上下文相结合的NC-value方法,为细粒度的专利分析服务如技术路线图绘制和技术演化分析等奠定了良好基础。
随着自然语言处理技术的进步和开放获取知识库的日益丰富,研究者逐渐将外部知识、语义信息、图结构、主题模型及深度学习等技术应用到术语抽取任务中。例如J. Vivaldi 等[51]使用维基百科类别的层次结构对候选术语进行有效性验证以提升术语抽取效果;与之不同,W. Wu等(2012)将维基百科的词条作为节点、词条之间的超链接作为边形成图结构,通过随机游走算法对所选概念赋权重来判断其是否是某技术领域中的术语;A. Judea 等(2014)提出一种大规模、无监督的高质量标注数据产生方法,用以训练专利术语抽取模型,并基于候选术语分类器和条件随机场的实证分析证明,这种方法不仅能够保持高准确率,同时还可以大幅提高召回率;主题模型用于术语抽取并不新鲜,E. Bolshakova等(2013)利用经典主题模型LDA(latent Dirichlet allocation)对特定领域术语进行抽取;虽然深度学习近年来横扫几乎自然语言处理领域的所有方向,但将其应用于术语抽取的研究并不多见,R. Wang 等[63]针对目前利用机器学习方法进行术语抽取时遇到的两个困境,即繁琐耗时的特征工程和特征选择以及标注数据的缺失,提出一种利用两个深度学习分类器实现的弱监督、自提升术语抽取方法,由于该方法旨在解决通用领域和专业领域面临的共同问题,其在有限标注数据上的良好表现预示着这一研究方向的良好前景。
4.2 命名实体识别
命名实体识别相比术语抽取更进一步,它不仅需要从文本中识别具有特定意义的词或者词组,而且需要给出其类型判断。在自然语言处理技术通常面临的文本如新闻、评论等,惯常定义的实体类型包括地址、人物、机构、货币、百分数、日期、时间等(The Stanford natural language processing group; GRANT I, THOMAS M, ANDREW F, et al, 2015)。然而专利文本中包含着对发明创新及其技术背景、实现细节和权利要求等内容的描述,其所定义的实体类型截然不同:S. Y. Yang等(2012)从工艺流程出发,将实体类型划分为方法、步骤、方式、属性、实体、值,将实体之间关系划分为动作、包含、前置,实体和关系可进一步细分为实际类型(real)、辅助类型(auxiliary)、领域依赖、领域无关等;S. Choi等(2012)侧重实体的句法特征和保存状态,将实体分为概念、主语概念、宾语概念、事实类型、部分事实类型、效果事实类型、概念状态、固体、气体、液体、场等;薛池等(2013)受到TRIZ思想影响(沈萌红, 2011),使用一种更加系统全面的概念模型,该模型将机械产品专利中的关系划分为层次关系、属性关系和功能关系,将实体划分为技术系统、流、属性,技术系统分为系统、零部件,流分为物流、能量流、信息流,属性分为性状、位置、方向、数量、几何、材料等;I. Bergmann等(2008)建立一套针对DNA芯片技术的细致的实体类型定义。
除了类型定义,在命名实体抽取方法上,自然语言处理和专利挖掘领域同样各具特点。前者经历了基于规则的方法、基于无监督聚类或弱监督自提升的方法、基于特征的有监督的方法以及深度学习方法4个阶段(LI J, SUN A, HAN J, et al, 2020),目前研究已经比较成熟,命名实体识别的效果超过90%(F1值)也屡见不鲜。然而达成这一效果通常需要充足的标注数据且标注语料和目标语料来自同一领域或者近似领域。但专利数据是典型的领域特定数据,不同技术领域的专利文本之间内容、特点迥异,这使某一技术领域的标注语料并不适用于其他技术领域命名实体识别模型的训练,且目前可公开获取的信息抽取标注语料库最大规模仅为3万条(PÉREZ-PÉREZ M, PÉREZ-RODRÍGUEZ G, VAZQUEZ M, et al, 2017)。因此,长期以来专利中命名实体识别选择了更实际和高效的做法,即在通用句法解析工具对专利文本进行句法解析和词性标注的基础上,使用规则匹配来识别命名实体的边界和类型。
当然,随着深度学习技术的溢出效应,将其应用于专利命名实体识别的工作逐渐开始出现,如F. Saad(2019)设计了一种基于BiLSTM改进的循环神经网络,从生物医药专利文本中抽取蛋白质、基因等实体;Z. Zhai等(2020)以BiLSTM-CNN-CRF为例,对生物医药专利数据集和化学专利数据集中进行命名实体识别,为提升识别效果和方便对比分析,他们使用来自相同领域的专利数据集训练出一套常规的Word2Vec词嵌入向量和一套能够感知上下文环境的ELMo词嵌入向量,其中后者在命名实体识别效果上较前者有明显改善;L. Chen等(2020)同样证实了训练自相同领域专利语料库的词嵌入向量会对该领域上自然语言处理任务(命名实体识别、语义关系抽取)的效果带来改善。
4.3 语义关系抽取
语义关系抽取旨在判断两个实体之间所存在的语义关系及其类型,按照语义关系的抽取对象范围不同,可分为句子级语义关系抽取、文档级语义关系抽取(或称句间语义关系抽取)以及语料库级语义关系抽取(LIU K, 2020)。目前专利挖掘中的语义关系抽取以句子级语义关系抽取为主,即从给定句子中识别实体之间的语义关系。由于这些方法以面向专利分析实际应用为主,具体方法多以流程形式呈现,内容较为繁碎,主要流程可概括如图2所示:
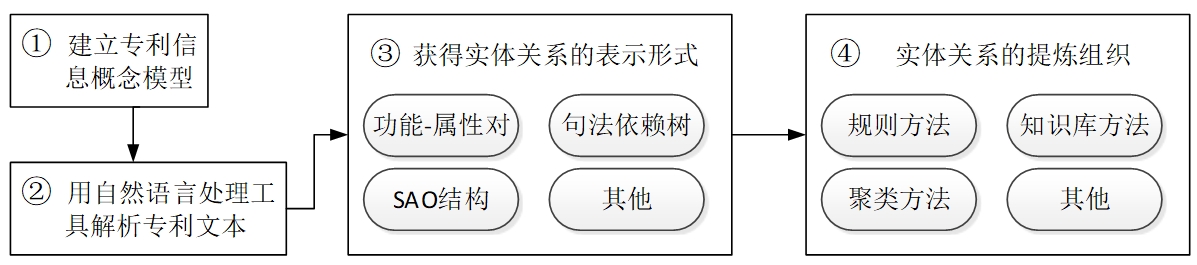
图2专利语义关系抽取流程
Figure 2 Procedure of semantic relation extraction from patents
步骤①和②与专利命名实体抽取类似,即首先建立专利信息概念模型,确定下语义关系的类型;之后使用句法解析工具获取句子中词汇的词性和句法依存关系,并在步骤③中使用人工规则筛选出其中可能的语义关系并采用结构化的方式表示。当前主要的结构化表示形式有SAO三元组和功能—属性对。所谓SAO,即句子中的主语(subject)、谓语(action)、宾语(object)成分,可组成三元组形式来表示文本中的实体语义关系。而在功能—属性对中,功能指系统可提供的有用行为,属性指系统或其子系统具有的某种性质[25]。相比较而言,功能—属性对的优势在于其本身即是TRIZ的重要组成部分,因而可以作为TRIZ的计算机实现手段来指导真实场景下的创新实践;而SAO三元组当初是为弥补向量空间模型的元素间缺乏语义关联而产生(胡正银,方曙, 2014),旨在发现专利之间的联系和区别。当然,随着研究的推进,这两种表示方式之间界限逐渐模糊,比如文献(Wang X, Ma P, Huang Y, et al, 2017; PARK H, YOON J, KIM K, 2013)等认为部分AO反映了技术所提供的功能,因而可以在SAO的基础上识别功能、属性。
由于专利语义关系抽取是建立在既定概念模式上的封闭关系抽取,所以步骤④的语义关系加工提炼需要将类型繁多的候选实体语义关系对应到固定有限的关系种类集合中,当前主流做法有规则方法和知识库方法。所谓规则方法,即总结归纳一套规则以实现从语义关系表示形式向语义关系的转化,S. Choi等(2013)建立了一套用词汇来判别S、O以及AO实体类型的规则,并根据判断所得实体类型将它们分配到包含产品、技术、功能3个层次的实体框架;J. Yoon等(2015)将AO分为产品可完成的任务、产品可改变的属性和产品结构3类,并给出各自的词构成规则和代表性词汇,来协助新SAO的类别判定并以此为基础来提炼语义关系;J.Yoon等(2012)先采用句法分析将包含创新概念的候选语义关系汇集起来,之后建立一套功能—属性融合规则来归并具有相同含义的语义关系。知识库方法通过对齐知识库中关系实例与专利中的候选语义关系,来完成语义关系的提炼,S. Choi等(2012)提出一种面向事实的本体方法来处理SAO,他们先将原始的SAO结构对应到由Wordnet中的词汇所组成的泛化SAO结构上,之后利用Wordnet中的概念层级关系将泛化SAO结构进一步抽象到专利信息概念模型上;在专利知识库构建上,S. Dewulf(2011)、J. Yoon等(2012)建立了以功能、属性为核心的知识库;J. Yoon等(2015)、X. Wang等(2015)、J. Yoon等(2012)、S. Choi等(2012)从SAO结构中抽取出产品、功能、技术信息并将其作为实体类型构建出类型不同的知识库,也有研究者尝试将Wordnet和产品设计语言Functional Basis相结合,以求在一个既定框架创建出具有明确规范限制的知识库(2012)。
相比术语抽取和命名实体识别,面向专利文本的语义关系抽取从关注单一事物转向探索事物之间的相互联系,从而使研究者以知识库的形式来呈现专利文本中零部件、原材料、科学概念、功能效果等技术要素之间及其与产品、市场的相互关系,从而更好地支持产品核心技术识别、技术转移转化、技术路线图构建、技术趋势分析等应用服务。然而,从上述综述来看该方向的研究探索并不充分,语义关系抽取中所存在的词汇和语法歧义问题没能得到很好解决;同时这些专利关系抽取方法在执行成本、效率以及可移植性、可扩展性上均存在种种不足。实际上近年来自然语言处理领域在该方向的技术进展尤其是深度学习方法对专利语义关系抽取具有很大的启发性。以2019年语言与智能竞赛为例,冠军团队在关系抽取任务上取得的F1值达到89.3%(WU H, 2019)这在之前难以想象的。背后有两个关键因素,一是大规模预训练模型的使用,二是高达21万条标注数据的支持。然而,这两个因素都需要巨大的人力、算力投入,即便谷歌提供了基于专利文献的BERT-for-Patents预训练模型,如何高效、低成本地生成大规模专利标注数据集,如何在同等标注工作量下优化关系抽取效果,以及如何在关系抽取建模时合理利用专利文本的特殊性仍然面临着巨大的挑战。L. Chen等(2022)在这方面做了一些探索性工作,他们发现专利文本相比普通文本包含更多词组型命名实体,且这些命名实体之间存在稠密的共词关系,利用图神经网络对这些共词关系建模以产生额外信息可以有效提升常规语义关系分类模型的效果。
4.4 跨篇章实体共指消解
为增加专利文本的理解难度、避免发明被竞争者发现、理解和复现(FANTONI G, APREDA R, DELL’ORLETTA F, et al, 2013),专利撰写者会使用一系列文字技巧,例如同义词、近义词、模糊术语、上下位概念替换、对等词等,使专利文本晦涩难懂、描述用语极为模糊,比如真空吸尘器被描述为“龙卷风产生装置”(KANAZASHI T, YONEDO K, 2000),文件扫描仪被描述为“光线扫描装置”(GOMI A, NOMURA Y, IKUMA K, 2009),而如何将出现在不同文献中指向相同实体的一组对等实体指称识别出来,即跨篇章实体共指消解(BEHESHTI S M R, BENATALLAH B, VENUGOPAL S, et al, 2017),则凸显出其超越单篇专利内部数据处理的重要价值。
该类方法的惯用特征包括词法特征、句法特征、基于知识库的特征以及实体之间的字符串匹配程度等。专利文本的特点会使这些特征在跨篇章实体共指消解中的效力大大减弱,需要研究者通过常识和领域知识加以弥补,而这些方面的研究成果还非常稀缺(CATTAN A, EIREW A, STANOVSKY G, et al, 2016),更多的实体共指消解研究聚焦于同一文档内部(BARHOM S, SHWARTZ V, EIREW A, et al, 2019),或者通过将实体指称映射到知识库的对应实体上,即实体链接(BARHOM S, SHWARTZ V, EIREW A, et al, 2019),来达成跨篇章实体共指消解的目的。抛开知识库相关方法后(目前此类方法所基于的通用知识库的内容对专利实体来说仍然过于宽泛),跨篇章实体共指消解方法仍然停留在传统机器学习方法阶段,主要依赖实体指称本身及其上下文的特征提取和相似度计算,对不同实体指称之间的关系进行度量,进而使用聚类算法将实体指称划归到指向不同实体的聚簇中(BEHESHTI S M R, BENATALLAH B, VENUGOPAL S, et al, 2017)。近三年来,已有学者尝试引入深度学习来完成这一任务,S. Barhom等(2019)受到H. Lee等(2012)的联合模型的启发,在事件参数(即实体指称)共指消解和事件本身共指消解在模型学习过程中相互激励的假设基础上,利用联合神经网络实现这一过程并分别在实体共指消解和事件共指消解上较独立神经网络提升1.2%和1%(p<0.001);2021年,A. Cattan等(2021)提出了第一个从纯文本中进行跨文档共指消解的端到端模型;同年,A. Caciularu等(2021)采用定制化预训练语言模型的方式来支持跨篇章实体共指消解,具体来说,他们基于Longformer模型将多个相关文档拼接起来作为模型输入并通过跨文档遮掩(cross-document masking)使模型学到长距离和跨文档关系,新模型在大幅减少训练参数的同时,其所产生的词嵌入在跨篇章实体共指消解和事件共指消解、论文引文推荐、文章剽窃探测等任务上均取得了新的最佳成绩,这些研究成果为解决跨篇章实体共指消解问题面临的普遍问题,可以直接用于专利文本或者对专利文本中开展此类工作具有重要启发作用。
4.5 小结
本类专利挖掘任务的目标比较明确,即处理专利数据以支持下游的应用需求,而专利数据处理方法本身并不直接提供业务服务能力。在技术实现上,此类任务一般可以转换为对应的机器学习或者自然语言处理任务,但由于专利数据和通用数据之间的显著差别,会导致这些机器学习或者自然语言处理任务在专利数据上存在一定的性能下降,而如何量化专利特点并在此基础上建模以提升效果,成为专利挖掘的重要研究方向;同时由于专利数据的领域依赖属性,不同技术领域的专利标注数据难以跨领域使用,这使得研究者们更加青睐以句法解析工具和人工规则方式进行免标注的数据处理,例如基于SAO结构和功能—属性对的关系抽取方法,但这些方法存在人工规则难以复用且抽取精度较低的问题,而如何低成本、大规模、高质量生成标注数据,以及在无标注或少标注前提下如何提升专利数据处理的效果,成为当前亟待解决的问题。
5. 面向专利信息服务的智能算法研究
当前面向专利信息服务的智能算法研究可以分为3类,如图1下半部分所示:其一是发展时间较长、成熟度较高、可以集成到软件平台并为常规专利业务开展提供基础服务的算法类型,比如案源分配、专利检索、专利翻译、信息可视化等;其二是利用信息技术实现专利分析服务自动化、智能化的算法类型,例如技术脉络识别、技术机会发现、合作伙伴推荐、技术热点探测等;其三是探索专利核心问题智能化解决方案的算法类型,包括专利无效判断、专利侵权诉讼、专利自动撰写、专利新颖性识别等。下文分别从这3类算法中挑选若干具有代表性的研究方向,对其发展脉络和重要成果进行梳理和阐述。
5.1 案源分配
当专利申请文件到达专利局后,需要对其所属技术类别进行标注以便分配给相应的审查员,这一环节被称为案源分配。由于科学技术的快速发展、社会各界知识产权保护意识的增强以及相关政策支持等多种原因,专利申请量屡创新高,以中国国家知识产权局为例,仅2020年上半年全国发明专利申请量就高达68.3万件。巨量的专利申请极大加重了审查员的工作负担,对专利审查的质量和效率提出了严峻的挑战。如何将机器学习技术引入案源分配、实现专利审查的提质增效成为一个亟待解决的重要问题。
案源分配中的技术分类体系,如IPC、CPC、USPC等均为层次分类体系。以IPC为例,它从上到下共分部、大类、小类、大组、小组5个层级,粒度从上到下逐步细化,具体如图3实例所示;IPC每年1月份更新一次,2021版IPC中包含了8个部、131个大类、646个小类、7 523个大组和68 899个小组(WIPO, 2021)。进行案源分配时,由于发明创新往往涉及多个技术类别,导致一个专利申请会被分配多个技术类别,从而使案源分配天然对应到自然语言处理领域的多标签文本分类任务,外加专利数据本身字段丰富、内容详尽、体量巨大,是合适的训练数据,使得针对这一任务的研究工作早在20世纪90年代已经出现(LARKEY L, 1998)。早期案源分配方法采用词袋(bag-of-word)和空间向量模型(space vector model)来表示专利文本内容,通过忽略词汇顺序来降低模型复杂度和算力需求,采用的分类模型包括支持向量机(FALL C J, TÖRCSVÁRI A, BENZINEB K, et al, 2003)、K近邻(LARKEY L, 1998)、朴素贝叶斯方法(LARKEY L, 1998)、Winnow算法(KOSTER C H A, SEUTTER M, BENEY J, 2003)等;也有研究从案源分配的特殊性上出发,从专利数据或者技术分类体系上优化特征或者分类算法,比如J.H.Kim等(2007)在专利文本表示中融入词汇之间的语义信息,并在日本专利分类任务上取得了74%的效果提升,L. Cai和T. Hofmann(2004)着眼于技术分类体系的层次结构,基于支持向量机拓展出一种层次分类方法,这种思路同样被D. Tikk等沿用(2008),他们将技术分类体系融入在线分类器并在WIPO-alpha和Espace A/B数据集上取得了良好效果。
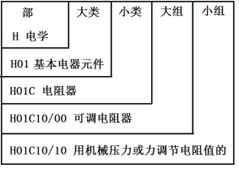
图3 IPC实例
Figure 3 IPC sample
近年来深度学习方法的突飞猛进为案源分配带来了新思路,即通过深度神经网络学习到的低维、稠密向量,来表示词汇、短语、句子、段落乃至整个篇章,进而将文档分类纳入深度学习的解决范围之内。吕璐成等(2020)系统汇总了卷积神经网络(convolutional neural network, CNN)、循环神经网络(recurrent neural network, RNN)、注意力机制等常见深度神经网络结构或数据特征权重分配方法,并结合词嵌入生成技术Word2Vec(MIKOLOV T, CHEN K, CORRADO G, et al, 2013)组配出7种文本分类模型用于测评其在中文专利案源分配上的效果,他们发现上下文特征和双向语序特征能有效提升案源分配效果,而注意力机制对关键数据特征的强化作用同样有助于判定专利类别。然而此类案源分类方法所基于的静态词嵌入技术(例如Word2Vec)将单一词汇恒定地对应到一个数值型向量上面而无法随上下文语境动态变化,并不符合自然语言一词多意的特点,对此研究人员提出了一系列能够根据上下文语境动态变化的动态词嵌入向量生成技术及其模型框架,例如BERT(DEVLIN J, CHANG M W, LEE K, et al, 2018)、ELMo(PETERS M , NEUMANN M, IYYER M,et al, 2018)、GPT(RADFORD A, NARASIMHAN K, SALIMANS T, et al)等,进而通过“预训练模型+微调”的模式把案源分配效果提升到新的高度,所谓微调(fine-tuning)即在原有模型参数权重的基础上使用特定任务数据集继续训练,以“轻微调整”模型参数权重的方式使其适应该任务并具备较强的任务完成能力。最早通过微调进行案源分配的模型是ULMFiT(HEPBURN J, 2018),但很快J. S. Lee等(2020)通过微调BERT刷新了当时的最佳案源分配效果;H. Bekamiri等(2021)利用RoBERTa产生专利类别伪标签来实现专利类别标注数据集的数据增强,进而将Sentence-BERT和K近邻算法相结合微调出超越J. S. Lee等(2020)的新型案源分配模型。
值得注意的是,上述模型虽然需要在专利数据上微调,但预训练阶段普遍采用的是通用语料,与其专利文本分类的目标并不匹配,从而影响了案源分配效果。对此谷歌基于1亿篇英文专利全文数据训练出专利版本的BERT模型,即BERT-for-Patents,在专利挖掘任务上具有明显优势,陈亮等(2022)在对中文专利进行案源分配时发现,即便在将中文专利翻译为英文的机器翻译过程中存在信息损失,使用BERT-for-Patents对翻译后的专利进行案源分配的效果也远优于使用中文通用版本BERT直接对中文专利进行案源分配。
5.2 专利检索
专利检索指根据一项数据特征,从大量的专利文献或专利数据库中挑选符合某一特定要求的文献或者信息的过程(陈燕, 黄迎燕, 方建国, 2006)。虽然专利检索属于信息检索大类,但相比普通信息检索,它具有自己鲜明的领域特色,包括由丰富的题录字段所导致复杂的检索方式、由多样的业务需求所导致种类繁多的检索目的,由详实的技术细节所导致冗长的检索词列表以及对检索高召回率的重视等(陈燕, 黄迎燕, 方建国. 2006; SHALABY W, ZADROZNY W, 2019)。进一步深入到专利文本中,不难发现专利在篇章、句子和词汇层面的特点都会给专利检索带来巨大的挑战,尤其是词汇特点,使得相当一部分专利文档与检索词语义匹配但词汇不匹配,是横亘在这一方向的最大难题。W. Magdy等(2009)统计专利检索数据基准CLEF-IP 2009(RODA G, TAIT J, PIROI F, et al, 2009)时发现,12%的相关专利与检索主题之间不存在词汇匹配。正面解决之道,包括集外词汇(out-of-vocabulary)的合理使用和同义挖掘目前仍属于开放性问题,困难重重。即便如此,研究者们依然做了大量工作来推动专利检索的进步,包括检索式重构(query reformulation)(SHALABY W, ZADROZNY W, 2019)、专利索引的扩充和优化等。
5.2.1检索式重构
这是专利检索中被广泛应用的一类技术,旨在通过扩展或简化检索式以提升相关文献的检索效果,具体方法可以分为3种类型:
(1)伪相关性反馈(pseudo-relevance feedback)。该方法从初始检索式的检索结果中选取排名靠前的专利文献,并利用这些专利文献对检索式进行扩展、简化,进而用更新后的检索式继续检索直至该过程迭代若干轮次(SHALABY W, ZADROZNY W, 2019)。伪相关反馈方法虽然因其较高的自动化程度和显著效果受到研究者和使用者的青睐,但仍然会因专利中同义词和模糊用语而产生主题漂移现象。对此,S. Bashir与A. Rauber(2009)对索引文档集合进行聚类,并将伪相关性反馈专利的选取限定在同一聚簇内;P. Mahdabi等(2012)根据专利丰富的题录信息,利用回归模型对反馈回来的专利进行再判断,以确定其相关性;另一方面,A. Fuji等(2007)使用引文关系替代相关性检索来获取反馈结果,由于专利引文尤其是审查员引文在揭示文档相关性上的精确性,这一方法取得了较大的性能提升。
(2)基于语义的方法也被称为基于附加的方法(appending-based methods)。该方法旨在通过外部或内部信息资源的协助,为检索式和相关专利之间架设起语义关联的桥梁。其中外部信息包括语义词典(如WordNet)、百科词典(如维基百科)、领域本体库(如UMLS)、技术分类编号说明书(如IPC)、专利检索日志甚至专利平行语料库( MAGDY W, JONES G J F, 2010),其作用在于通过直接或者间接方式,为专利检索词提供同义词、近义词乃至上位词清单以减少专利检索的漏检;内部信息通常指检索条件中的主题专利本身,具体来说,研究者以主题专利为数据来源来扩展或简化检索关键词,比如从专利说明字段中识别技术详释句子以优化检索词( MAGDY W, JONES G J F, 2010),或者利用从主题专利中抽取与检索词存在语义关系的其他词汇并填充到检索词列表(KRISHNAN A, CARDENAS A F, SPRINGER D, 2010;NGUYEN K L, MYAENG S H, 2012),有的国内专利检索平台也提供了类似功能(详见合享新创专利检索平台的AI检索)。
(3)基于题录数据的方法。利用专利中丰富的题录数据来指导专利检索词的选取,是另一种可选择的检索式重构方式,但重构过程通常比较复杂。比如利用伪相关反馈结果绘制一个查询条件对应的引文网络,并利用PageRank为网络中的每个专利打分,之后使用得分对引文网络中文档集合的词汇分布进行限制和查询模型的参数估计,并利用求解的模型进行检索式扩展(MAHDABI P, CRESTANI F, 2014);或者利用技术分类号、发明人、专利权人产生加权专利引文网络,并利用时间感知的随机游走算法(time-aware random walk)对专利打分和利用高分专利对检索式进行扩展(MAHDABI P, CRESTANI F., 2014)。
5.2.2专利索引的扩充和优化
专利具有丰富的题录字段和详实的技术细节,这些特点为专利检索系统提供了广阔的优化空间,也留下了必须解决的技术问题:如何在索引层面解决词汇匹配和语义匹配之间的割裂?如何适应用户惯常用长文本甚至整篇专利作为检索条件的检索方式?如何扩充和优化索引?如何在工程实践上保障检索效果和检索效率的平衡?下面分别展开介绍。
(1)语义检索。实际上,语义检索技术可以在一定程度同时解决前两个问题。其做法是在词汇和文档之间创建一个潜在语义空间,并将含义彼此关联和相近的词汇汇集在同一维度,即主题(topic)。在该检索系统中,表示一篇文档的方式是基于潜在语义的低维、稠密向量,而专利检索将不再依赖具体词汇而是从主题层面进行文件对比。这从一定程度上缓解了同义词、近义词、模糊用语所带来的困扰,同时避免了词汇层次表示方式所带来的无词共现文档之间相似性无法度量的问题。虽然从算法实现上讲,潜在语义索引(latent semantic indexing)(LANDAUER T K, FOLTZ P W, LAHAMD, 1998)和主题模型方法家族(ALGHAMDI R, ALFALQI K, 2015)均可以生成文档的潜在语义表示,而业界也提供了相应的向量搜索引擎,如Faiss、Milvus、Proxima等,开源搜索引擎ElasticSearch自 7.0版本以后开始支持稠密向量检索,但从使用者角度来说这些还不够,在语义检索模型中合理引入和使用高质量领域词表会对使搜索引擎在对抗专利词汇特点和提升检索效果上起到重要作用。
(2)索引的扩充和优化。多字段检索是当前专利检索系统的常规功能,其底层实现通常是首先在搜索引擎中设置或者默认不同字段的检索权重。当检索专利时,文本字段使用相似度匹配,题录字段使用布尔匹配,最后将索引中各个文档按照不同字段得分加权求和并降序输出结果。但这种做法也遗留了若干问题,其一是如何为各个字段赋予合理权重;其二是如何保持检索速度和检索效果的平衡;其三是如何挖掘不同字段之间乃至不同文档之间的联系。随着机器学习和信息检索的深度结合,人们逐渐采用学习排序方法(learning to rank)(LIU T Y, 2011)来解决第一个问题。所谓学习排序,即旨在解决文档排序问题的、基于特征和判别式训练的、能够根据相关性反馈自动调节信息检索系统参数的机器学习技术。具体来说,该方法将检索式与索引中不同字段之间的匹配值作为特征,检索式对应的相关文档作为金标准,进而采用判别式模型为索引字段分配权重,使加权字段所产生的排序结果尽可能逼近金标准。然而,在工程场景下专利索引中的文档数量通常是千万级别,而由此产生的训练数据则更是海量。为平衡检索速度和检索效果,一种被广泛采用的方法是将检索过程划分为两个阶段:①检索召回阶段,通过传统布尔检索式快速从专利索引中获取排名靠前的候选专利列表,以压缩训练数据规模;②精准排序阶段,对候选专利列表使用计算密集的学习算法以优化检索结果排序,具体框架如图4所示:
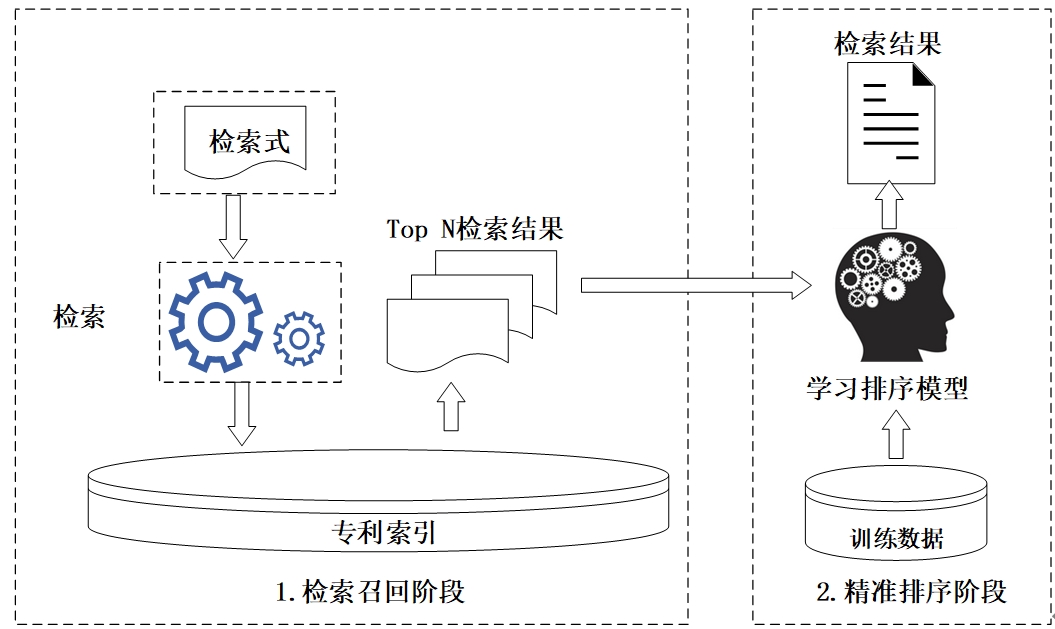
图4 两阶段专利检索框架
Figure 4 Two-stage patent information retrieval framework
在挖掘不同字段之间以及不同文档之间的联系上,一种可取的方法是采用元路径(meta-path)将不同字段串联起来形成新的索引字段。所谓元路径,即定义在网络模式(network schema)上的链接两个对象的一条路径,比如可以在专利信息网络模式,即图5(a)上从专利到专利游走得到元路径示例1和例2,如图5(b)(c)所示,并利用专利数据集在元路径上的计数或者随机游走得分作为路径两端专利之间的关系测度(SUN Y, HAN J, 2012)。研究显示(FU T, LEI Z, LEE W C, 2015;苟妍,2020),元路径特征可以显著提升对专利检索中相关文件的检出效果,但由于并非任意专利之间都会存在某些元路径,在这种情况下,其相应的索引字段会存在数据缺失问题。随着图深度网络的崛起,将其应用于由不同文档之间关联关系,如引文关系、共词关系、共技术分类号关系等所形成的网络上,进而将每个文档的网络结构信息内聚到图嵌入向量的做法开始出现。将这种图嵌入向量应用于专利检索,可以一定程度上消除专利词汇特点所带来的不利影响并起到提升专利检索效果的作用(CHOI S, LEE H, PARK E L, et al, 2019; 师英昭, 2021)。
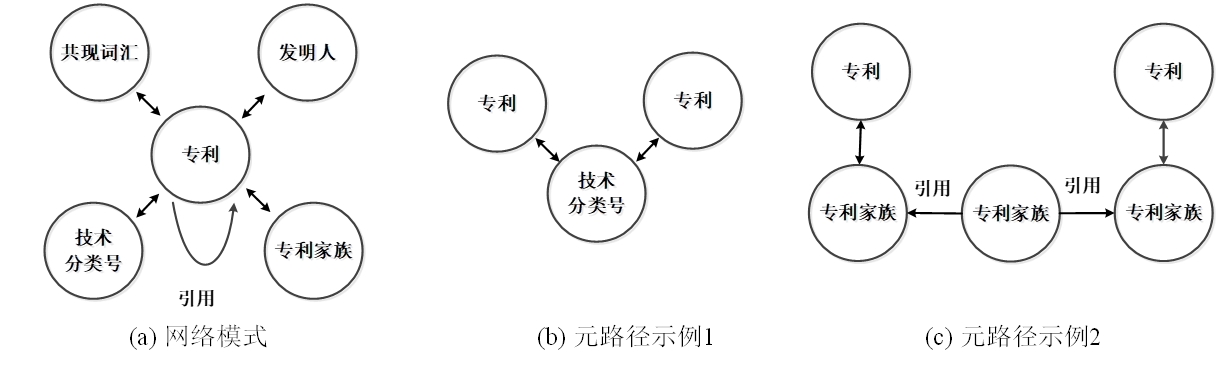
图5 元路径示意
Figure 5 Meta-path sample
(a) Network model (b) Meta-path sample 1 (c) Meta-path sample 2
5.3 技术路线图
技术路线图(technology roadmap)又叫专利地图,目前尚无统一定义,原因是它实践性较强,不同使用者使用技术路线图的侧重点不同,使用的技巧和表现形式也存在差异(黄鲁成,李欣,吴菲菲, 2010)。两个比较有代表性的定义如下:R. Galvin认为技术路线图是针对某一特定领域,集合众人意见对重要变动因素所作的未来的展望(1998),世界知识产权组织定义技术路线图是对专利分析全部结果的可视化表达,通过对目标技术领域相关专利信息进行搜集、处理和分析,使复杂多样的专利情报得到方便有效的理解(WIPS Co. Ltd)。
专利中的结构化数据和非结构化数据均可用于技术路线图的绘制。在基于结构化数据的技术路线图绘制方法中,一种简易方法是将专利结构化数据的不同字段加以组合,比如将技术分类号和专利权人地域相组合所展示的地域技术分布图;将专利数和专利权人数相组合并按照年度顺序将各个节点连起来所形成的专利技术生命周期图。但这种基于计数方式的技术路线图对专利信息的挖掘力度有限,与之相比,基于专利引文网络的技术路线图方法能够从网络整体结构出发,对节点、连线以及路径的重要程度以及彼此的差异性展开深入分析,因而占据着更为重要的位置,例如M. E. Mogee等(1999)、S. H. Chena等(2012)对专利引文网络上进行聚类操作,之后通过分析聚簇之间的关系随时间变化情况来识别技术演化;E. Garfield(1994)基于被引频次可以反映节点重要程度的视角,提出一种将高被引文献串联起来以反映整个引文网络中知识流动的关键路径法,但这种方法并没有将施引情况考虑在内;与此不同,N. P. Hummon与P. Doreian(1989)提出一个着眼继承先前知识积累、更强调为后来研究发挥重要参考作用的引文路径生成算法,并称其为主路径分析法,由于这一算法有效减少了人为干预、具有良好的分析效果,外加社会网络分析软件Pajek(http://vlado.fmf.uni-lj.si/pub/networks/pajek/)将主路径分析功能集成进来,大大降低了使用门槛,使得这一方法很快从专利数据扩散到论文数据甚至法律文书数据上;同时,为囊括更多子技术的发展轨迹,为主路径添加更多细节补充信息,研究者们又提出一系列主路径方法的变体,包括多主路径方法(LIU J S, LU Y Y L, LU W M, et al, 2013)、key-route主路径方法(LIU J S, LU Y Y L, LU W M, et al, 2013; XIAO Y, LU L Y, LIU J S,et al, 2014)、基于语义信息的主路径方法(陈亮, 杨冠灿, 张静,等, 2015)等。
相比结构化数据,专利中的非结构化数据,即文本字段承载着专利的核心内容,也是技术路线图绘制的重要原料。基本文本分析法如词频分析法、词汇共现分析法等通过提取专利项、摘要和标题中的技术关键词,并根据它们的出现频次或共词网络分析来获取技术领域的研究状况和发展趋势(肖国华,郭捷婷, 2008)。随着研究的深入,学者们逐渐将一些文本挖掘领域的成熟方法引入进来。B. Yoon等(2004)借鉴空间向量模型思想,提出一种以关键词向量为基础,绘制专利网络关联图的分析方法;G. Young等(2008)在专利—关键词矩阵基础上,以关键词所在专利的最早申请日期为横轴、关键词的出现频次为纵轴创建专利网络图,以揭示技术主题随时间变化的演变趋势;方曙等(2011)在该方法基础上,采用专利号取代关键词作为专利文档聚类的基础,关系矩阵的数值取值同时考虑分类号在专利文档中的分布特征以及分类号之间的语义特征,在聚类时采用更适合中小数据量的系统聚类分析法;陈亮等(2015)将文本挖掘方法和主路径分析法相结合,使用引文网络中相邻节点所依附文本之间的文本相似度作为引文连线的权重,来识别不同技术主题的技术演化脉络;更近一步,他们基于路径上所依附的文本信息将引文网络中的备选路径聚类到不同的子领域,进而从每个子领域中抽取代表其发展脉络的主路径,从而全面反映技术领域的发展轨迹(2022)。
除了技术演化分析,技术路线图的另一个重要用途是将专利内容可视化展现,以反映技术全景(technology landscape)、发现技术机会和分析专利布局,H. Uchida等(]UCHIDA H, MANO A, YUKAWA T)将奇异值分解方法应用于专利—词汇矩阵以得到专利文本的降维表示,进而利用层次聚类法获取技术全景;类似地,S. Lee等(2009)通过主成分分析法将专利文档投射到二维平面,其中空白及散点稀疏的区域即为需要重点关注的可能的技术空白点;汤森路透的专利分析软件Aureka也提供类似功能;另一方面,B. Yoon等(2004)建立起基于文本相似度的专利关系网络,并设计技术中心指数、技术周期指数、技术关键词聚类指数3个指标以识别潜在的技术机会;王亮等(2015)将主题模型应用于专利文献,他们利用HDP模型可以自动确定主题数量的特点,通过分析不同时间窗内主题的分流与合流,来展示技术布局的动态变化情况。
5.4 专利价值评估
专利价值包括两个方面,其一是给专利所有者所带来的经济价值,其二是为整个社会带来的科学和技术福祉。专利价值这种经济属性和社会属性使得早期相关研究由经济学家推动,他们从逻辑角度提出了一系列专利价值的影响因素和测度指标( Reitzig M, 2003; Allison J R, Lemley M A, Moore K A, et al, 2003)。Nordhaus (1967)早在1967年就将专利寿命列入专利价值的影响因素;1990年,Klemperer (1990),Gilbert & Shapiro(1990)引入专利宽度(Patent-breadth),即专利权利要求的覆盖范围作为专利价值的另一个重要影响因素;在后续研究中,不断有更多影响因素和测度指标加入进来,比如创造行为(inventive activity)(Greene J R& Scotchmer S, 1995)、技术公开(disclosure) [166]、围绕某专利的创新难度(difficulty to invent around)(Gallini N T, 1992)等等,我们将重要的专利价值影响因素和测度指标进行了梳理汇总如表5、6所示。
表5 专利价值影响因素汇总
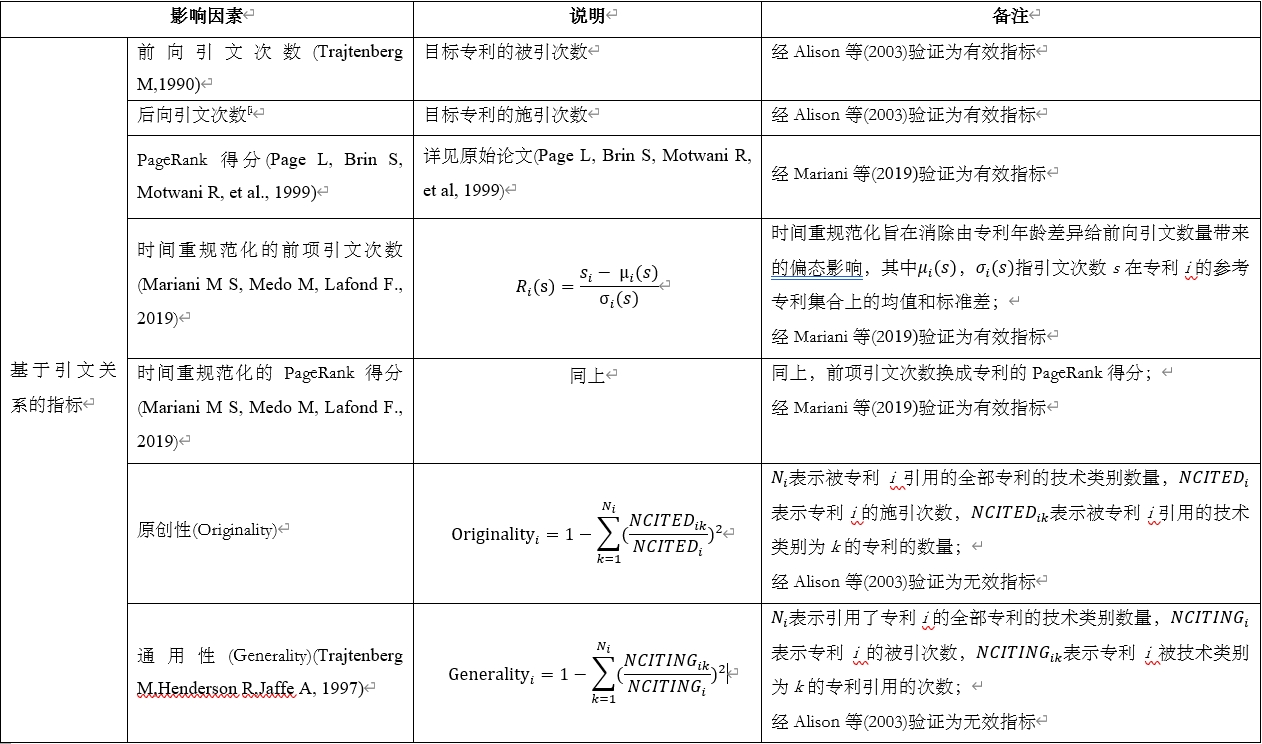
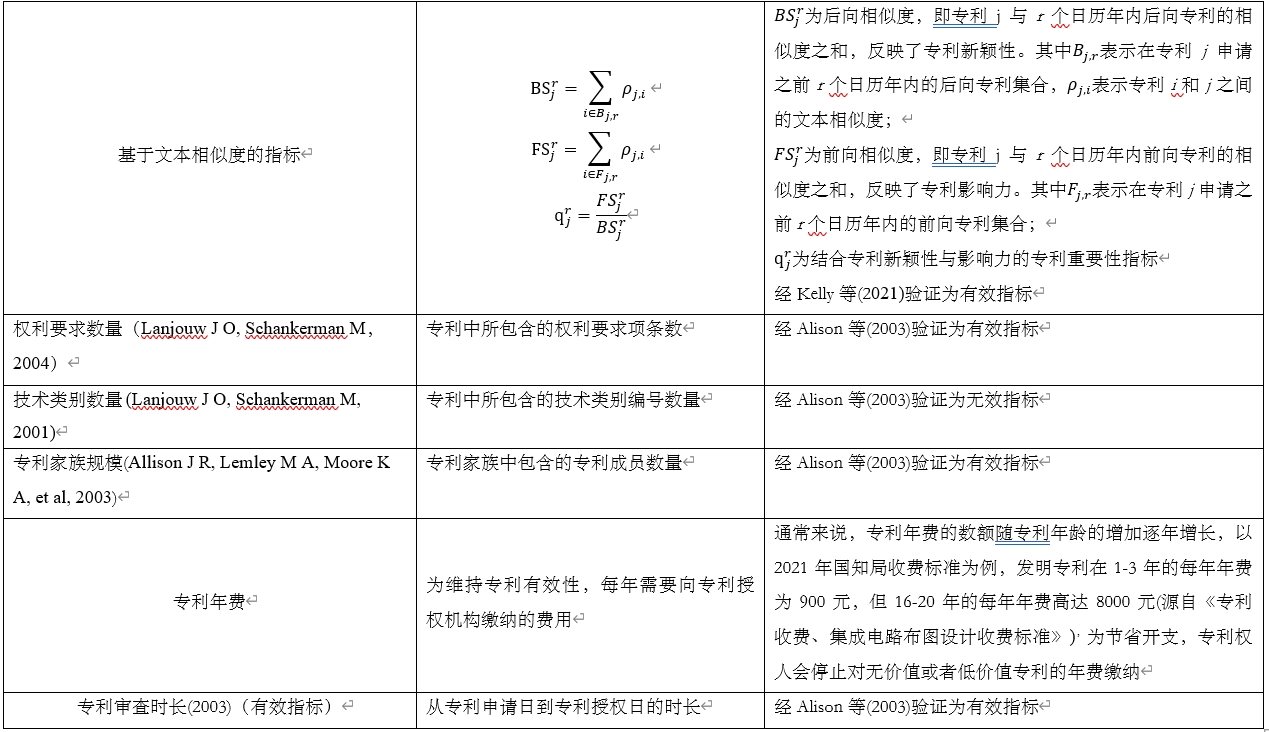
表6 专利价值影响因素汇总

然而这些专利价值的影响因素和测度指标并没有经过假设检验验证,仍然停留在理论探讨层面。2003年,Allison等(2003)基于1966年至1999年近300万美国专利数据,从数据科学角度对部分指标的有效性进行了验证,在剔除无效指标的同时,他们提出两个新指标,即专利家族规模和专利审核时长,这份研究成果为后续利用机器学习技术进行专利价值预测奠定了良好基础,而相关论文也被业界认为是知名专利检索平台Innography中经典的专利价值测度指标-专利强度的技术白皮书。 但即便如此,距离利用智能算法对专利价值进行预测仍然有很长一段路要走。原因在于有些影响因素难以度量,比如绕过某专利的创新难度;还有些影响因素不仅在乎专利本身,更多需要通过与其他专利对比才能显现出来,比如专利的新颖性、创造性。虽然不乏有研究工作简单的将专利价值评估作为文本分类问题(Chung P, Sohn S Y, 2020),更多研究者将包含专利对比和关联的结构信息纳入专利价值评估模型中,比如Yang等( Yang G C, Li G, Li C Y, et al., 2015)将直接引文、间接引文、共被引和耦合四种专利引文关系加以融合以实现对专利价值的判断;Lin等(2018)利用不同的神经网络将专利引文网络结构、节点属性以及节点所依附的文本内容内化到不同的节点表示向量中,将这些向量拼接并输入全连接层训练后,就可以得到专利的价值预测输出;Kelly等(2021)基于一个观察,即重要专利是指与在先工作存在较大差别但后续创新存在密切关联的专利,他们提出一套基于文本相似度的指标,分别对一个专利与其在先专利集合和后续专利集合的关联性进行测度,并利用这两个关联性的比值作为专利重要性的度量指标,虽然这一研究所基于的观察最初由Shaparenko等(2011)在识别重要文献时提出,但这并不影响这篇文章的启发性,它利用简单技术就揭示了一种新的专利新颖性测度方式,并且展现出相比传统专利被引次数的多重优势。
5.5专利撰写
根据撰写目的不同,专利撰写可分为生成(generation)、摘要(summarization)、简化(simplification)3种方式(CASOLA S, LAVELLI A, 2021)。专利生成指利用计算机技术自动撰写专利全文或者部分文本如专利权利要求项;专利摘要旨在将单一或者多个专利的内容压缩成较短文本,使其包含原始专利的主要内容;专利简化则对句法、语法复杂,内容晦涩难懂的专利文本进行简化,使其在信息无损的情况下提高专利的可读性,下面分别对其展开叙述。
5.5.1专利生成
研究专利生成技术的动机很直观,专利申请文书的撰写需要考虑专利法、专利局规章制度和专利审查程序等一系列要求,发明人通常难以独立应对,要向专利律师或者专利代理人求助或者请其代为撰写,这中间产生的费用非常高昂,比如在美国通常超过几千美金(PETRUZZI J D, MASON R M, 2000)。为节省成本,同时为避免专利发明人和专利律师、专利代理人之间的信息沟通出现偏差,有关专利生成技术的专利申请早在1996年已经出现(PETRUZZI J D, MASON R M, 2000),其方法将专利中的发明信息分为4类,即相比在先专利的优势、主要技术组件、次要技术组件、可替代组件,并使用文本模板将这些内容组织起来作为专利申请文书的草案;J. Glasgow(2011)采用分层和分类方式对技术发明的内部结构进行图形化表示,并以用户互动方式生成与图形化表示相一致的专利文本格式;与此不同,K. Knight等(2020)将专利权利要求及其在说明书中对应的支持文本标记出来以训练机器学习模型,从而使模型具备为给定权利要求项自动补齐支持文本的能力。
相比专利申请,专利生成技术相关学术论文的出现则是随着GPT-2、BERT等预训练模型的问世而发生。S. Lee和J. Hsiang(2020)利用2013年美国专利商标局授权的55万多件专利的第一独立权利要求项训练GPT-2模型并考察其在有条件和无条件下的专利权利要求项撰写能力;他们进一步对专利中不同文本字段进行配对,比如(标题,摘要)(摘要,独立权利要求项)(独立权利要求项、非独立权利要求项),并分别将这些配对文本放入GPT-2中训练,使其具备从一个字段推导另一个字段的能力,以(标题,摘要)配对文本为例,输入某专利的标题使GPT-2输出该专利的摘要(LEE S, HSIANG J, 2020)。然而,这一方向存在两个问题亟待解决,即如何控制专利文本生成过程使其符合使用者的意图和如何评估生成专利的质量,第一个问题目前仍处于开放状态;对于第二个问题,S. Lee(2020)使用文本相似度对专利质量的重要指标之一——新颖性进行度量,认为理想的生成专利应该位于与当前最接近的技术有一定的距离但又不太遥远的Goldilocks地带,符合这一标准的生成专利可以作为优先结果。实际上,专利新颖性的判断是一个非常复杂的问题,需要在排除专利词汇干扰的基础上综合考量目标专利与最接近现有技术在技术领域、所解决的技术问题、技术方案和预期效果上的关系,才能给出一个合理的判断。
5.5.2专利摘要
一般来说,专利摘要方法分为抽取式(extractive summarization)、生成式(abstractive summarization)两种方法。其中抽取式方法相对简单,它主要从原始文档中选择信息量最大的词汇、句子甚至段落并形成摘要结果(CASOLA S, LAVELLI A, 2021);生成式方法根据对原始文本的理解来形成摘要,模型试图理解文本的内容以生成原文中没有的单词,因而更接近摘要的本质(OKAMOTO M, SHAN Z, ORIHARA R, 2017)。就目前发展态势来说,专利摘要仍然以抽取式方法为主。但值得注意的是,随着深度学习对自然语言处理各个方向的横扫,尤其是大型专利摘要数据集BigPatent(SHARMA E, LI C, WANG L, 2019)的发布,生成式专利摘要不仅引起了专利挖掘研究者的关注,由于专利文本不同于常规文本的显著特点,这一任务也极大激发了机器学习领域学者的研究热情(CASOLA S, LAVELLI A, 2021)。
从自然语言处理范畴来讲,文本摘要的总体技术框架为:内容表示à权重计算à内容选择à内容组织,其中内容表示是将原始文本划分为文本单元并转化为机器学习模型使用的输入形式,具体指对文本进行分词、抽词干、去停用词等文本预处理并转化为空间向量模型、主题模型、图、词嵌入等表示形式;权重计算是计算文本单元的权重评分,计算方式包括基于特征评分、标注序列、分类模型的评分方法;内容选择指对赋权重的文本单元进行筛选并构成摘要候选集;内容组织是对候选集的内容进行整理并形成最终摘要(李金鹏, 张闯,陈小军,等, 2021)。专利文本摘要的技术路线虽然遵从上述框架,但技术方案类型收窄许多,以抽取式方法为例,其内容表示主要通过标点符号和启发式规则将文档拆分为片段、句子和段落,并进行文本预处理来实现;权重计算以特征抽取方法为主,包括获取关键词、线索词、句子在篇章或段落中的位置等;最后将抽取的句子合并起来形成摘要结果。至于专利文本摘要的生成式方法,早期研究借助人工规则将浅层句法结构映射为深层句法结构,从而获得一种近似的语义表示并用以生成文本摘要(MILLE S, WANNER L, 2008);随着近年来深度学习方法的崛起,学者们倾向于以一种端到端的方式,利用深度学习模型从输入文本中学到其潜在的语义表示向量,进而将其转化为文本摘要输出,E. Sharma等(2019)在提供BigPatent的同时,也发布了若干专利文本摘要基线模型,包括集成注意力机制的LSTM、具备和不具备覆盖的指针—生成器(pointer-generator with or without coverage)以及SentRewriting;A. J. C. Trappey等(2020)注意到德温特创新检索平台对晦涩难懂的专利摘要进行了人工改写以突出其新颖性、用途和优势,这是绝佳的专利文本摘要金标准,他们提出一种集成注意力机制的序列到序列模型SSWA(sequence to sequence with attention)以实现生成式专利摘要,该模型在控制智能、智能决策和感应器智能3个子领域的德温特创新检索平台数据上取得了平均准确率/召回率为90%/84%的成绩。
5.5.3专利简化
专利文本尤其是权利要求项晦涩难懂,利用专利简化技术提升专利文本的可读性无论对于普通用户,还是对领域专业人员均具有重要价值。值得注意的是,专利简化和专利摘要虽然均是对专利原文进行改写,但两者存在核心区别,即专利简化中并没有内容方面的删减。当前主要的专利简化技术包括内容重写和对自由文本进行结构化信息抽取、可视化展现。一种较为直接的内容重写方式是不改变文本字面本身,只对文本结构进行重构,例如G. Ferraro等(2014)对专利权利要求项进行简化,他们首先使用GATE工具开发了一种规则方法,将每条权利项要求划分为序言、过渡和正文,之后针对正文中句子冗长、复杂的特点,使用条件随机场套件CRF++(https://taku910.github.io/crfpp/)来识别其中的子句边界,从而完成权利要求项的拆分和简化;与此不同,PATExpert(WANNER L, BRÜGMANN S, DIALLO B, et al)平台为用户提供了一个释义模块,以重新组织文字的方式简化专利文本,其具体过程分为两个步骤,即用浅层语法规则把专利文本分解成更小更简单的亚结构,和使用预定义规则融合和转化亚结构并生成专利文本(WANNER L, BRÜGMANN S, DIALLO B, et al; 费一楠, 张钊, 2013)。除产出简化后的自由文本外,利用信息抽取技术将专利内容结构化和可视化也是一种有效的专利简化方式,在该方向上,M. Okatomo等(2017)提供了一个面向专利文本的可视化界面,为方便专家对比权利要求项和查找相似专利,该界面用不同颜色标记专利的发明类型、权利要求项的相互依赖关系、专利文本中的技术组件以及它们在权利要求项中的参考情况;更进一步,L. Andersson等(2013)以实体及其之间的相互联系为基础将专利文本转化为语义关系网络,从而消除自由文本所具备的非结构性和歧义性;J. Kang等(2018)使用PATExpert从专利中抽取技术问题、部分问题或者参数,进而拼装成发明设计方法的本体结构,对于单篇专利来说,由于其文本内容被转化为问题和解决方法,因此可读性得到提高。
5.6专利诉讼
专利诉讼是一种由潜在专利引起的、发生在企业之间的、以阻击竞争对手商业发展为目的的诉讼事件(KRESTEL R, CHIKKAMATH R, HEWEL C, et al,2021)。在专利挖掘和机器学习的交叉地带,专利诉讼研究主要聚焦在专利的专利性判定上,其中以预测可能引起法律诉讼的专利(后面简称诉讼专利识别)最为典型。当前该问题被作为分类问题加以研究,即从专利信息中提炼特征和训练分类模型,从而将引起诉讼的专利从专利数据集合中识别出来。虽然引起专利诉讼的原因很多,背后逻辑较为复杂,但分类方法将这一任务大大简化,以便在机器学习视角探索专利诉讼的影响因素和及其重要程度,为下一阶段的技术选型奠定良好基础。V. Raphupathi等(2018)梳理了美国联邦巡回上溯法院(U.S. court of appeals for federal circuit)在医药领域专利无效诉讼案件中考虑的11个影响因素,即创造性、发明描述是否清晰、实用性、可预见性、等同原则、反诉条款、安全港条款、保护期限延长、可由法院审理的争议、不公平的行为(如故意隐瞒)以及有意拖延行为,不难发现其中大部分影响因素难以量化。替代地,S. Juranek与H. Otneim调研了27个专利属性如权利要求数量、技术领域、后向引用数量、专利家族大小等,他们将这些属性作为特征输入到Logistic回归模型中进行诉讼专利预测,从而度量出各个属性对预测结果的贡献程度;在此基础上,W. Campbell等进一步将专利文本和引文关系网络作为特征添加进来,他们分别将专利文本输入Logistic回归、将引文关系输入随机森林以预测诉讼专利,之后将这两个分类器连同包含专利题录的Logistic回归模型作为基分类器、选用Logistic回归模型作为元分类器进行学习和预测,实验结果显示在诉讼专利预测中各类特征的贡献从大到小依次是元数据、引文网络和文本内容。值得注意的是,相对总的专利数量来说,引起过诉讼的专利只占1%[165],因此基于分类方法的诉讼专利预测研究,除了存在将预测依据的搜寻范围限定在目标专利本身这个先天缺陷外,同时也面临着训练数据中正负样本极端不平衡的困扰。
从业务逻辑来看,诉讼专利预测被包夹在由一系列任务所形成的工作流中间,这条工作流包含研读专利法律条文、对给定专利进行现有技术状况和专利全景检索、分析技术文件和给定专利之间的语义关联和技术关联、压缩技术文件范围和选择对比文件、预测诉讼专利(CAMPBELL W, LI L, DAGLI C, et al)、认定相关破坏依据等。长远来看,专利诉讼预测的发展需要在现有对目标专利自身的研究基础上,将外部文件尤其是对比文件与目标专利之间复杂的相互作用纳入考量范围。所谓对比文件,即用来判断目标专利是否具备新颖性、创造性等所引用的相关文件(详见专利审查指南(2010)的543-578页)。在这个方向上,Q. Liu等(2018)做出了一些有益的尝试,其利用卷积神经网络和张量分解从原告、被告以及专利的题录和文本信息中提炼专利内容和协同信息,并将其应用于算法训练使目标专利引起诉讼的概率要大于非目标专利引起诉讼的概率,虽然该模型的评测方法相比真实场景有一定松弛,但从评测结果来看该模型仍然具有一定效果。
除研究问题本身的困难外,高质量训练数据集的缺乏同样是横亘在研究者面前的障碍,对此,J. Risch等(2020)利用欧洲专利局自2012年起在发布专利公告时附带专利检索报告的有利条件,发布了一个包含专利权利要求项、对比文献的对应段落以及有效无效标签的专利诉讼数据集PatentMatch,样本规模高达600万,为后续研究奠定了良好基础,此外,J. Risch等(2020)还提供一个基于BERT的基线模型,即将权利要求项和相关专利中对应段落拼接后输入BERT以预测权利要求项能否被无效掉,但该模型效果不佳,仅略高于随机猜测;美国专利商标局同样将专利诉讼案件卷宗数据集,即PTAB (patent trial and appeal board)[17]数据集公诸与众,目前该数据集仍在不断扩充更新中;在该数据集基础上,K. Rajshekhar等(2017)着眼于诉讼专利预测的前趋任务,即压缩技术文件范围和选择对比文件,从信息检索的角度进行技术验证,发现只有不到15%的目标专利和对比文件之间存在强语义匹配,而与对比文件非强语义匹配却使目标专利无效的案例占比至少为20%(RAJSHEKHAR K, SHALABY W, ZADROZNY W,2016),此外,他们使用了基于子领域语料库训练的词嵌入向量并将其集成到对比文件检索过程中,在常用检索指标recall@100下将检索效果从5%提升到20%。
5.7 小结
近年来面向专利信息服务的智能算法研究取得了极大的进展,具体体现在3个方面:①专利基础服务支撑能力得到了加强,例如在海量训练语料和深度学习算法的加持下,案源分配算法已经能够输出较高质量的专利分类结果并成为专利审查提质增效的重要组成部分;②技术情报分析服务逐步由基于题录数据的统计分析和依赖专家智慧的定性研判走向数据驱动下全文本、细粒度、多字段的专利内容深度挖掘;③专利挖掘的前沿探索逐步触及专利实务核心问题,例如专利侵权诉讼、专利无效判定、专利新颖性识别等,而相关研究成果更是拓广了人们对专利数据作用和价值的认识边界。同时,不难发现存在于本研究方向的两条鸿沟:普适性的通用人工智能和垂直领域高度特化的专利挖掘算法之间的鸿沟以及技术方法探索和业务实践应用之间的鸿沟。当前通用人工智能技术无法通过简单套用为专利挖掘提供系统性解决方案,而对于某些涉及专利核心问题的技术攻关,例如专利诉讼、新颖性识别,即便存在标注数据集支持,由于这些问题处于当前人工智能技术的边缘甚至边界以外,目前研究方向依然不够明朗。
6. 总结与前瞻
本文对近年来与专利挖掘研究相关的论文、专利、竞赛评测、数据集、模型、代码、信息服务平台等材料进行了全面调研,以形成从专利数据、模型文件到技术方法的系统梳理,为数据驱动型人工智能的背景下探讨国内外专利挖掘研究发展现状和未来态势提供全局视角。不难发现,近年来专利挖掘取得了显著进步,这种进步包括:①专利挖掘方法在自动化、智能化和精确度上取得了长足进步,虽然之前综述专利挖掘时统计学习方法、线性代数方法如词袋模型、支持向量机和潜在语义分析还占据重要地位,同时诸多专利挖掘任务需要借助人工规则和专家智慧才能得以完成,但如今越来越多学者转向深度神经网络、图机器学习和预训练模型等前沿领域去实现技术升级和性能提升,而使用统计学习方法、人工规则、软件工具完成的专利挖掘任务也以更加优化和合理的方式实现学习成本、实践成本和方法效果之间的平衡;②专利挖掘方法的覆盖范围从专利数据处理、规范化蔓延到专利基础服务支撑和技术情报分析,并逐步逼近专利实务的核心问题,不仅如此,越来越多研究者投身专利数据资源建设,这不仅为模型训练提供了必备原料、有效避免重复造车轮,也为不同方法之间的性能对比准备了统一测度标准,为产生权威、可信赖的方法评测结果准备了必要条件;③ 基础资源与智能算法的结合日益密切并逐步形成专利挖掘研究发展的新模式,这不仅体现在数据型基础资源是推动智能算法发展的强大动力,更体现在在CNN、RNN等常规深度神经网络架构、预训练模型逐渐承担更多专利挖掘任务和大语言模型日渐崛起的大背景下,算法模型更多地以词嵌入向量词典和模型检查点的形式在研究者之间以及研究者和用户之间交流、使用并推动算法向前发展,模型检查点和词嵌入向量词典利用模型参数容纳训练数据中的知识以形成隐性知识库,传统数据与算法之间的清晰边界正变得模糊。
同时专利挖掘研究发展也存在一些不足和困难,包括:①专利全文尚未得到充分研究,虽然专利全文是解决专利技术方案抽取、区别技术特征识别、专利新颖性、创造性测度等一系列关键问题的必备数据,研究价值巨大且获取相对便利,但当前以专利全文作为研究对象的学术成果仍然寥寥,同时专利中图片信息以及图片—文本多模态信息的价值也未被充分发掘;②专利基础资源对专利挖掘算法研究的推动作用远未得到兑现,这反映出专利基础资源在智能技术社区受到的关注度普遍不高,部分专利问题虽然重要且有基础资源支持,但研究进展缓慢,例如PatentMatch数据集所对应的专利诉讼研究目前仍然停留在探索研究方向的阶段,而PhraseMatching除被用来在Kaggle上举办过算法竞赛外,并未产生其他有影响力的成果;③针对专利数据独特特点和专利业务独特需求的智能算法研究成果还不多见,大数据和人工智能赋能的专利挖掘研究尚处于开始阶段,虽然研究内容形形色色、布局较广,但相当数量研究成果是通用技术在专利数据上的直接应用,随着研究进入深水区,会有更多反映专利领域特点的问题出现在通用人工智能的技术边界之外,需要研究者一方面量化专利特点并将其转化为智能算法性能的增长点,一方面对专利业务特有问题独立建模,以形成具备专业领域特色的发展方式。
最后,近期以ChatGPT大语言模型为代表的通用智能模型的崛起及其优异表现,不仅给全社会带来了极大冲击,也使专利挖掘发展面临着全新的思考。大语言模型意味着一种全新的智能算法开发和应用模式,该模式下不再针对单一任务设计算法,而是在具备海量知识储备、语义理解能力和文字生成能力的超大规模模型底座下,将各类算法任务通过精心设计的文字模板转化为不同形式的问句(即prompt)交给大语言模型统一解决。大语言模型向人们展示了通用人工智能的可能性,但也存在各种缺陷和不足,包括:①大语言模型执行应答任务虽然极其消耗算力,但应答效率不高(尤其当输入的prompt较长时),在部分任务的效果上也低于专有模型,并不适合执行包含大批量数据处理的专利挖掘任务,然而对于需要融合专业知识和世界常识才能解决的问题,例如专利无效判别,大语言模型可能是一个突破方向;②大语言模型输出存在虚假编造内容,即幻觉问题,同时它的数学能力也无法让人信赖,但专利挖掘任务更多是信息抽取、检索以及有事实依据的知识推理问题,而开放性问题和数学问题并不多见,因此基于大语言模型的专利挖掘研究重点在于专利挖掘问题细分、本地知识库建设以及问题和候选答案的精准匹配机制构建,让大语言模型尽可能在本地知识库所产生的有限空间内选择而非自动生成答案的关键信息,同时发掘大语言模型分解复杂问题并使用代理工具组装解决方案的能力;③大语言模型的训练语料通常是通用语料,这使得它们难以为专利从业者和领域技术人员提供专业应答。虽然J. S. Lee(2023)使用731G美国专利全文数据从头训练出PatentGPT-J-6b等模型,但该模型迄今并没有经过有监督微调和基于人类反馈强化学习的优化,尚不具备应答问题的能力,如何在此类垂直领域大语言模型基础上形成专利信息服务能力和业务增长点,也是未来的重要研究内容。
参考文献
ACM. SIGIR: special interest group on information retrieval[EB/OL].[2023-11-26].
https://www.acm.org/special-interest-groups/sigs/sigir.
AKHONDI S A, KLENNER A G, TYRCHAN C, et al. Annotated chemical patent corpus: a gold standard for text mining[J]. Plos one, 2014, 9(9): e107477.
ALGHAMDI R, ALFALQI K. A survey of topic modeling in text mining [J]. International journal of advanced computer science and applications, 2015, 6(1): 147-153
Allison J R, Lemley M A, Moore K A, et al. Valuable patents[J]. Georgetown Law Journal, 2003, 92: 435-493
ANDERSSON L, LUPU M, HANBURY A. Domain adaptation of general natural language processing tools for a patent claim visualization system[C]//Information retrieval facility conference. Heidelberg: Springer, 2013: 70-82.
ASLANYAN G, Wetherbee I. Patents phrase to phrase semantic matching dataset[J]. arXiv preprint arXiv:2208.01171, 2022.
BARHOM S, SHWARTZ V, EIREW A, et al. Revisiting joint modeling of cross-document entity and event coreference resolution[J]. arXiv preprint arXiv:1906.01753, 2019.
Bashir S, Rauber A. Improving retrievability of patents with cluster-based pseudo-relevance feedback documents selection[C]//Proceedings of the 18th ACM conference on Information and knowledge management. 2009: 1863-1866
BEHESHTI S M R, BENATALLAH B, VENUGOPAL S, et al. A systematic review and comparative analysis of cross-document coreference resolution methods and tools[J]. Computing, 2017, 99(4): 313-349.
BERGMANN I, BUTZKE D, WALTER L, et al. Evaluating the risk of patent infringement by means of semantic patent analysis: the case of DNA chips[J]. R&D management, 2008, 38(5):550–562.
BEKAMIRI H, HAIN D S, JUROWETZKI R. Patentsberta: a deep nlp based hybrid model for patent distance and classification using augmented sbert[J]. arXiv preprint arXiv:2103.11933, 2021.
BOLSHAKOVA E, LOUKACHEVITCH N, NOKEL M. Topic models can improve domain term extraction[C]//European conference on information retrieval. Heidelberg: Springer, 2013: 684-687.
CACIULARU A, COHAN A, BELTAGY I, et al. Cross-document language modeling[J]. arXiv preprint arXiv:2101.00406, 2021.
CASOLA S, LAVELLI A. Summarization, simplification, and generation: the case of patents[J]. arXiv preprint arXiv:2104.14860, 2021.
CATTAN A, EIREW A, STANOVSKY G, et al. Cross-document coreference resolution over predicted mentions[J]. arXiv preprint arXiv:2106.01210, 2021.
CAMPBELL W, LI L, DAGLI C, et al. Predicting and analyzing factors in patent litigation. [EB/OL].[2023-11-28].http://www.mlandthelaw.org/papers/campbell.pdf.
CAI L, HOFMANN T. Hierarchical document categorization with support vector machines[C]//Proceedings of the thirteenth ACM international conference on information and knowledge management. New York: ACM, 2004: 78-87.
CHEN L, XU S, ZHU L, et al. A deep learning based method for extracting semantic information from patent documents[J]. Scientometrics, 2020, 125(1): 289-312.
CHEN L, XU S, ZHU L, et al. A semantic main path analysis method to identify multiple developmental trajectories[J]. Journal of informetrics, 2022,16(2):101281.
CHEN L, XU S, ZHU L, et al. A deep learning based method benefiting from characteristics of patents for semantic relation classification[J]. Journal of informetrics, 2022, 16(3):101312.
CHENA S H, HUANG M H, CHENA D Z. Identifying and visualizing technology evolution: a case study of smart grid technology[J]. Technological forecasting and social change, 2012, 79(6): 1099-1110.
CHOI S, KANG D, LIM J, et al. A fact-oriented ontological approach to SAO-based function modeling of patents for implementing function-based technology database[J]. Expert system with application, 2012, 39(10):9129-9140.
CHOI S, KIM H, YOON J, et al. An SAO-based text-mining approach for technology road mapping using patent information[J].R&D management, 2013,43(1):52-73.
CHOI S, LEE H, PARK E L, et al. Deep patent landscaping model using transformer and graph embedding [J]. arXiv preprint arXiv:1903.05823, 2019.
CHOI S, PARK H, KANG D, et al. An SAO-based text mining approach to building a technology tree for technology planning[J].Expert system with application, 2012, 39(13):11443-11455.
Chung P, Sohn S Y. Early detection of valuable patents using a deep learning model: Case of semiconductor industry[J]. Technological Forecasting and Social Change, 2020, 158: 120146.
CLEF-Initiative-a. The CLEF Initiative conference and labs of the evaluation forum [EB/OL].[2023-11-26].http://www.clef-initiative.eu/.
CLEF-IP 2009 Download area [EB/OL].[2023-11-26].http://www.ifs.tuwien.ac.at/~clef-ip/download/2009/index.shtml#data.
CLEF-IP 2010 Download area [EB/OL].[2023-11-26].http://www.ifs.tuwien.ac.at/~clef-ip/download/2010/index.shtml.
CLEF-IP 2011 Download area [EB/OL].[2023-11-26]. http://www.ifs.tuwien.ac.at/~clef-ip/download/2011/index.shtml.
CLEF-IP 2012 Download area [EB/OL].[2023-11-26]. http://www.ifs.tuwien.ac.at/~clef-ip/download/2012/index.shtml.
CLEF-IP 2013 download area [EB/OL].[2023-11-26]. http://www.ifs.tuwien.ac.at/~clef-ip/download/2013/index.shtml.
CLEF-Initiative-b. CLEF-IP image tasks guidelines[EB/OL].[2023-11-26] .http://www.ifs.tuwien.ac.at/~clef-ip/download/2011/docs/CLEF-IP2011-IMG_tasks_guidelines.pdf.
CLEF-Initiative-c.CLEF-IP 2013 Download area [EB/OL].[2023-11-26]. http://www.ifs.tuwien.ac.at/~clef-ip/download/2013/index.shtml
DEVLIN J, CHANG M W, LEE K, ET AL. Bert: pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.DEWULF S. Directed variation of properties for new or improved function product DNA, a base for connect and develop[J].Procedia engineering. 2011,(9):646-652.
Gallini N T. Patent policy and costly imitation [J]. The RAND Journal of Economics, 1992, 23 (1): 52–63
EVANS D A, LEFFERTS R G. Clarit-TREC experiments[J].Information processing and management, 1995, 31(3): 385–395.
FALL C J, TÖRCSVÁRI A, BENZINEB K, et al. Automated categorization in the international patent classification[C]//AcmSigir Forum. New York: ACM, 2003, 37(1): 10-25.FRANTZI K, ANANIADOU S, MIMA H. Automatic recognition of multi-word terms[J]. International journal of digital libraries, 2000, 3(2): 117-132.
FANTONI G, APREDA R, DELL’ORLETTA F, et al. Automatic extraction of function–behaviour–state information from patents[J]. Advanced engineering informatics, 2013, 27(3), 317-334.
FERRARO G, SUOMINEN H, NUALART J. Segmentation of patent claims for improving their readability[C]//Proceedings of the 3rd workshop on predicting and improving text readability for target reader populations (PITR). Stroudsburg: ACL, 2014: 66-73.
FRUMKIN J,MYERS A. Cancer moonshot patent data (August, 2016) [EB/OL].[2023-11-26]. https://bulkdata.uspto.gov/data/patent/cancer/moonshot/2016/cancer_patent_data_doc_v15. Docx.
FU T, LEI Z, LEE W C. Patent citation recommendation for examiners[C]//2015 IEEE international conference on data mining. Rosten: IEEE, 2015: 751-756.
FUJI A. Enhancing patent retrieval by citation analysis[C] // Proceedings of the 30th annual international ACM SIGIR conference on research and development in information retrieval. New York: ACM, 2007: 793-794.
GALVIN R. Science roadmaps[J]. Science, 1998, 280(8): 803.
GARFIELD E. Research fronts [J]. Current contents, 1994, 41(10): 3-7.
Gilbert R, Shapiro C. Optimal patent length and breadth [J]. The RAND Journal of Economics, 1990, 21(1): 106-112.
GLASGOW J. Automated system and method for patent drafting and technology assessment: US8041739[P].2011-10-18. [2023-11-28]. https://image-ppubs.uspto.gov/dirsearch-public/print/downloadPdf/6082387.
GOBEILL J, TEODORO D, PASCHE E, et al. Report on the TREC 2009 experiments: chemical IR track [EB/OL].[2023-11-28]. http://bitem.hesge.ch/sites/default/files/biblio/Report_on_the_trec_2009_experiments_Chem.pdf .
GOMI A, NOMURA Y, IKUMA K. Light scanning apparatus and method to prevent damage to an oscillation mirror, reducing its amplitude, in an abnormal control condition via a detection signal outputted to a controller even though the source still emits light: US7557976[P]. 2009-07-07.[2023-11-28]. https://image-ppubs.uspto.gov/dirsearch-public/print/downloadPdf/7557976
Google. BERT for patents [EB/OL].[2023-11-26].https://github.com/google/patents-public-data/blob/master/models/BERT%20for%20Patents.md.
GRANT I, THOMAS M, ANDREW F, et al. Taming text: how to find, organize and manipulate it[M].Greenwich: Manning Publications, 2015.
Greene J R, Scotchmer S. On the division of profit in sequential innovation [J]. The RAND Journal of Economics , 1995, 26 (1): 20–33
HALL B H, JAFFE A B, TRAJTENBERG M. The NBER patent citation data file: lessons, insights and methodological tools [EB/OL].[2023-11-28]. https://www.nber.org/system/files/working_papers/w8498/w8498.pdf.
HE J,NGUYEN D Q,AKHONDI S A, et al. Overview of ChEMU 2020: named entity recognition and event extraction of chemical reactions from patents[C]// Experimental IR Meets Multilinguality, Multimodality, and Interaction: 11th International Conference of the CLEF Association. Heidelberg: Springer, 2020: 237-254.
HEPBURN J. Universal language model fine-tuning for patent classification[C]// Proceedings of the Australasian Language Technology Association workshop 2018. Stroudsburg: ACL, 2018: 93-96.
HUMMON N P, DEREIAN P. Connectivity in a citation network: the development of DNA theory [J]. Social networks, 1989, 11(1): 39-63.
HUNT, D, NGUYEN, L, RODGERS, M. Patent searching: tools & techniques [M]. Hoboken: John Wiley & Sons, 2012.
JUDEA A, SCHÜTZE H, BRÜGMANN S. Unsupervised training set generation for automatic acquisition of technical terminology in patents[C]//Proceedings of the 25th international conference on computational linguistics. Stroudsburg: ACL, 2014: 290-300.
JURANEK S, OTNEIM H. Using machine learning to predict patent lawsuits. [EB/OL].[ 2023-11-28]. https://hdl.handle.net/11250/2760583.
KANAZASHI T, YONEDO K. Tornado generation method and apparatus:US6082387 [P]. 2000-07-04.[2023-11-28]. https://image-ppubs.uspto.gov/dirsearch-public/print/downloadPdf/6082387
KANG J, SOUILI A, CAVALLUCCI D. Text simplification of patent documents[C]//International TRIZ future conference. Heidelberg: Springer, 2018: 225-237.
Kelly B, Papanikolaou D, Seru A, et al. Measuring technological innovation over the long run[J]. American Economic Review: Insights, 2021, 3(3): 303-20.
KIM H B, HYEOK Y J, KIM K S. Semantic SAO network of patents for reusability of inventive knowledge[C]// IEEE international conference on management of innovation and technology. Rosten: IEEE, 2012:510-515.
KIM J H, CHOI K S. Patent document categorization based on semantic structural information[J]. Information processing & management, 2007, 43(5): 1200-1215.
Klemperer P. How broad should the scope of a patent be? [J]. The RAND Journal of Economics, 1990, 21(1): 113–130
KNIGHT K, SCHICK I C, PRIYADARSHI J. Machine learning model for computer-generated patent applications to provide support for individual claim features in a specification: US10713443[P]. 2020-07-14. [2023-11-28]. https://image-ppubs.uspto.gov/dirsearch-public/print/downloadPdf/10713443
KOSTER C H A, SEUTTER M, BENEY J. Multi-classification of patent applications with winnow[C]//International Andrei Ershov memorial conference on perspectives of system Informatics. Heidelberg: Springer, 2003: 546-555.
KRESTEL R, CHIKKAMATH R, HEWEL C, et al. A survey on deep learning for patent analysis[J]. World patent information, 2021, 65(6): 102035.
KRISHNAN A, CARDENAS A F, SPRINGER D. Search for patents using treatment and causal relationships[C]//Proceedings of the 3rd international workshop on patent information retrieval. New York: ACM, 2010: 1-10.
LANDAUER T K, FOLTZ P W, LAHAMD. An introduction to latent semantic analysis[J].Discourse processes, 1998,25(2/3): 259–284.
Lanjouw J O, Schankerman M. Characteristics of patent litigation: a window on competition[J]. RAND journal of economics, 2001: 129-151.
Lanjouw J O, Schankerman M. Patent quality and research productivity: Measuring innovation with multiple indicators[J]. The Economic Journal, 2004, 114(495): 441-465.
LARKEY L. Some issues in the automatic classification of US patents[C]//Working notes for the AAAI-98 workshop on learning for text categorization. Menlo Park: AAAI, 1998: 87-90.
LEE H, RECASENS M, CHANG A, et al. Joint entity and event coreference resolution across documents[C]//Proceedings of the 2012 joint conference on empirical methods in natural language processing and computational natural language learning. Stroudsburg: ACL, 2012: 489-500.
LEE J S. Evaluating generative patent language models[J]. World patent information, 2023, 72: 102173.
LEE S. Measuring and controlling text generation by semantic search[C]//Companion proceedings of the Web conference 2020.New York: ACM, 2020: 269-273.
LEE J S, HSIANG J. Patent classification by fine-tuning BERT language model [J]. World patent information, 2020, (61): 101965.
LEE S, HSIANG J. Patent claim generation by fine-tuning OpenAI GPT-2[J]. World patent information, 2020(62): 101983.
LEE S, HSIANG J. PatentTransformer-2: controlling patent text generation by structural metadata[J]. arXiv preprint arXiv:2001.03708, 2020.
LEE S, YOON B, PARK Y. An approach to discovering new technology opportunities: keyword-based patent map approach [J]. Technovation, 2009, 29(6/7): 481-497.
LEVIN R C. A new look at the patent system [J]. The American economic review, 1986, 76(2): 199-202.
LI J, SUN A, HAN J, et al. A survey on deep learning for named entity recognition [J]. IEEE transactions on knowledge and data engineering, 2020, 34(1): 1-20.
LI Y, FANG B, HE J, et al. The ChEMU 2022 Evaluation Campaign: Information Extraction in Chemical Patents[C]// Advances in Information Retrieval. Heidelberg: Springer, 2022: 400-407.
Lin H, Wang H, Du D, et al. Patent quality valuation with deep learning models[C]//International Conference on Database Systems for Advanced Applications. Springer, Cham, 2018: 474-490.
LIU K. A survey on neural relation extraction[J]. Science China technological sciences, 2020 (63): 1971-1989.
LIU J S, LU Y Y L, LU W M, et al. Data envelopment analysis 1978-2010:a citation-based literature survey[J]. Omega, 2013, 41(1): 3-15.
LIU Q, WU H, YE Y, et al. Patent litigation prediction: a convolutional tensor factorization approach[C]// Proceedings of the 27th international joint conference on artificial intelligence. Burlington: Morgan Kaufmann, 2018: 5052-5059.
LIU T Y. Learning to rank for information retrieval [J]. Foundation and trends in information retrieval,2011, 3(3): 225-331.
LUPU M, HUANG J, ZHU J, et al. TREC-CHEM: large scale chemical information retrieval evaluation at TREC[C]//ACM SIGIR forum. New York: ACM, 2009, 43(2): 63-70.
LUPU M, TAIT J, HUANG J, et al. Trec-chem 2010: notebook report [EB/OL].[2023-11-28].. https://trec.nist.gov/pubs/trec19/papers/CHEM.OVERVIEW.pdf
LUPU M, ZHAO J, HUANG J, et al. Overview of the TREC 2011 Chemical IR Track [EB/OL].[2023-11-28]. https://trec.nist.gov/pubs/trec20/papers/CHEM.OVERVIEW.pdf
MAHDABI P, CRESTANI F. Query-driven mining of citation networks for patent citation retrieval and recommendation[C]//Proceedings of the 23rd ACM international conference on conference on information and knowledge management. New York: ACM, 2014: 1659-1668.
MAHDABI P, CRESTANI F. Learning-based pseudo-relevance feedback for patent retrieval[C]//Information retrieval facility conference. Berlin:Springer, 2012: 1-11.
MAHDABI P, CRESTANI F. The effect of citation analysis on query expansion for patent retrieval[J]. Information retrieval, 2014, 17(5/6): 412-429.
MAGDY W, JONES G J F. Applying the KISS principle for the CLEF-IP 2010 prior art candidate patent search task. [EB/OL].[2023-11-28]. https://doras.dcu.ie/15834/.
MAGDY W, LEVELING J, JONES G J F. Exploring structured documents and query formulation techniques for patent retrieval[C]//Workshop of the cross-language evaluation forum for European languages. Berlin:Springer, 2009: 410-417.
MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space[J]. arXiv preprint arXiv:1301.3781, 2013.
MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality[EB/OL].[2023-11-26]. https://proceedings.neurips.cc/paper/2013/ file/ 9aa42b31882ec039965f3c4923ce901b-Paper.pdf.
MILLE S, WANNER L. Multilingual summarization in practice: the case of patent claims[C]//Proceedings of the 12th annual conference of the European Association for Machine Translation. Stroudsburg: ACL, , 2008: 120-129.
MOGEE M E, KOLAR R G. Patent co-citation analysis of Eli Lilly& Co. patents [J].Expert opinion on therapeutic patents,1999,9(3):291-305.
Narin F, Noma E, Perry R. Patents as indicators of corporate technological strength[J]. Research policy, 1987, 16(2-4): 143-155.
NGUYEN K L, MYAENG S H. Query enhancement for patent prior-art-search based on keyterm dependency relations and semantic tags[C]//Information retrieval facility conference. Berlin:Springer, 2012: 28-42.
Nordhaus W D. The optimal life of a patent [R]. Cowles Foundation for Research in Economics, Yale University, 1967.
NTCIR-a. NTCIR-7 PATMT (Patent translation test collection)[EB/OL].[2023-11-26].http://research.nii.ac.jp/ntcir/permission/ntcir-7/perm-en-PATMT.html.
NTCIR-b. NTCIR-8 PATMT (Patent translation) Research purpose use of test collection[EB/OL].[2023-11-26].http://research.nii.ac.jp/ntcir/permission/ntcir-8/perm-en-PATMT.html.
NTCIR-c. NTCIR-8 PATMT (patent translation) research purpose use of test collection
[EB/OL].[2023-11-26].http://research.nii.ac.jp/ntcir/permission/ntcir-8/perm-en-PATMT.html.
NTCIR-d. NTCIR (NII Testbeds and community for information access research) project[EB/OL].[2023-11-26].http://research.nii.ac.jp/ntcir/index-en.html
NTCIR Project test collections - DATA [EB/OL].[2023-11-26]. http://research.nii.ac.jp/ ntcir/permission/data-en.htm
OKAMOTO M, SHAN Z, ORIHARA R. Applying information extraction for patent structure analysis[C]//Proceedings of the 40th international ACM SIGIR conference on research and development in information retrieval. New York: ACM, 2017: 989-992.
PARK H, YOON J, KIM K. Using function-based patent analysis to identify potential application areas of technology for technology transfer[J]. Expert systems with applications, 2013, 40(13):5260-5265.
PÉREZ-PÉREZ M, PÉREZ-RODRÍGUEZ G, VAZQUEZ M, et al. Evaluation of chemical and gene/protein entity recognition systems at BioCreative V.5: the CEMP and GPRO patents tracks[C]//Proceedings of the BioCreative V.5 challenge evaluation workshop. Barcelona: UPC, 2017: 11-18.
PETERS M , NEUMANN M, IYYER M,et al. Deep contextualized word representations[J]. arXiv preprint arXiv:1802.05365, 2018.
PETRUZZI J D, MASON R M. Machine for drafting a patent application and process for doing same: US6049811[P]. 2000-04-11.[2023-11-28]. https://image-ppubs.uspto.gov/dirsearch-public/print/downloadPdf/6049811
PORTER A, CUNNINGHAM S. Tech mining: exploiting new technologies for competitive advantage [M]. Hoboken: John Wiley & Sons, 2004.
RADFORD A, NARASIMHAN K, SALIMANS T, ET Al. Improving language understanding by generative pre-training[EB/OL].[2023-11-26]. https://www.mikecaptain.com/resources/pdf/GPT-1.pdf.
RAGHUPATHI V, ZHOU Y, RAGHUPATHI W. Legal decision support: exploring big data analytics approach to modeling pharma patent validity cases[J]. IEEE access, 2018, 6(7): 41518-41528.
RAJSHEKHAR K, SHALABY W, ZADROZNY W. Analytics in post-grant patent review: possibilities and challenges (preliminary report)[C]//Proceedings of the American Society for Engineering Management 2016 international annual conference, .Red Hook: Curran Associates, Inc., 2016.
RAJSHEKHAR K, ZADROZNY W, GARAPATI S S. Analytics of patent case rulings: empirical evaluation of models for legal relevance[C]//Proceedings of the 16th international conference on artificial intelligence and law.New York: ACM, 2017.
Reitzig M. What determines patent value? Insights from the semiconductor industry [J]. Research policy, 2003, 32(1): 13-26
RICHARD M. Technical documentation for the 2019 patent examination research dataset (PatEx) release. [EB/OL].[2023-11-28]. https://www.uspto.gov/sites/default/files/documents/ PatEx-2019-Technical-Doc.pdf.
RISCH J, ALDER N, HEWEL C, et al. PatentMatch: a dataset for matching patent claims & prior art[J]. arXiv preprint arXiv:2012.13919, 2020.
RISCH J, KRESTEL R. Domain-specific word embeddings for patent classification [J]. Data technologies and applications, 2019, 53(1):108-122.
RODA G, TAIT J, PIROI F, et al. CLEF-IP 2009: retrieval experiments in the intellectual property domain[C]//Workshop of the cross-language evaluation forum for European languages. Berlin:Springer, 2009: 385-409.
SAAD F. Named entity recognition for biomedical patent text using Bi-LSTM variants[C]//Proceedings of the 21st international conference on information integration and Web-based applications & services. New York: ACM, 2019: 617-621.
SHALABY W, ZADROZNY W. Patent retrieval: a literature review [J]. Knowledge and information systems, 2019 (61): 631–660.
Shaparenko B, Caruana R, Gehrke J, et al. Identifying temporal patterns and key players in document collections[C]//Proceedings of the IEEE ICDM workshop on temporal data mining: Algorithms, theory and applications (TDM-05). 2005: 165-174.
SHARMA E, LI C, WANG L. Bigpatent: a large-scale dataset for abstractive and coherent summarization[J]. arXiv preprint arXiv:1906.03741, 2019.
SHEN W, WANG J, HAN J. Entity linking with a knowledge base: issues, techniques, and solutions[J]. IEEE transactions on knowledge and data engineering, 2014, 27(2): 443-460.
SUN Y, HAN J. Mining heterogeneous information networks: principles and methodologies [J]. Synthesis lectures on data mining and knowledge discovery, 2012, 3(2): 1-159.
The Stanford natural language processing group. Stanford named entity recognizer (NER). [EB/OL].[2023-08-18].http://nlp.stanford.edu/software/CRF-NER.shtml.
TIKK D, BIRÓ G, TÖRCSVÁRI A. A hierarchical online classifier for patent categorization[M]//Emerging technologies of text mining: techniques and applications. IGI Global, 2008: 244-267.
Track 2- CHEMDNER-patents[EB/OL].[2023-11-26] .
https://biocreative.bioinformatics.udel.edu/tasks/biocreative-v/track-2-chemdner/
TRAPPEY A J C, TRAPPEY C V, WU J L, et al. Intelligent compilation of patent summaries using machine learning and natural language processing techniques[J]. Advanced engineering informatics, 2020, 43: 101027.
UCHIDA H, MANO A, YUKAWA T. Patent map generation using concept-based vector space model[EB/OL].[2023-08-26]. http://research.nii.ac.jp/ntcir/ntcir-ws4/NTCIR4-WN/PATENT/NTCIR4WN-PATENT-UchidaH.pdf.
U.S. Patent Phrase to Phrase Matching[EB/OL].[2023-11-28]. https://www.kaggle.com/c/us-patent-phrase-to-phrase-matching
USPTO-a. USPTO-2M. [EB/OL].[2023-11-28]. https://github.com/JasonHoou/USPTO-2M.
Vienna University of Technology. MAREC[EB/OL].[2023-11-26].https://www.ifs.tuwien.ac.at/imp/marec.shtml.
USPTO-b. Patent trial and appeal board (PTAB) API[EB/OL].[2023-11-26]. https://uspto.data.commerce.gov/dataset/Patent-Trial-and-Appeal-Board-PTAB-API/nfzn-tgjt/data.
VIVALDI J, CABRERA-DIEGO L A, SIERRA G, et al. Using Wikipedia to validate the terminology found in a corpus of basic textbooks[EB/OL].[2023-11-26]. https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=30b3efe82d97b6974c0a11d0750d994723826954.
WANG R, LIU W, MCDONALD C. Featureless domain-specific term extraction with minimal labelled data[C]//Proceedings of the Australasian Language Technology Association workshop 2016. Stroudsburg: ACL, 2016: 103-112.
Wang X, Ma P, Huang Y, et al. Combining SAO semantic analysis and morphology analysis to identify technology opportunities[J]. Scientometrics, 2017, 111(2): 3-24.
WANG X, QIU P, ZHU D, et al. Identification of technology development trends based on subject-action-object analysis: the case of dye-sensitized solar cells[J].Technological forecasting and social change, 2015(98):24-46.
WANNER L, BRÜGMANN S, DIALLO B, et al. PATExpert: semantic processing of patent documentation [EB/OL].[2023-11-18]. http://ftp.informatik.rwth-aachen.de/Publications/ CEUR-WS/Vol-233/p51.pdf.
WIPO. IPC 2021.01 – Statistics[EB/OL].[2023-11-26].https://www.wipo.int/ classifications/ipc/ en/ITsupport/Version20210101/transformations/stats.html.
WIPS Co. Ltd, Patent map(PM). [EB/OL].[2023-11-10]. http://www.wipo.int/edocs/mdocs/sme/en /wipo_ip_bis_ge_03/wipo_ip_bis_ge_03_16-annex1.pdf.
WU H. Report of 2019 language & Intelligence technique evaluation. Baidu Corporation [EB/OL].[2023-11-18]. http://tcci.ccf.org.cn/summit/2019/dlinfo/1101-wh.pdf
WU W, LIU T, HU H, et al. Extracting domain-relevant term using Wikipedia based on random walk model[C]//Proceeding of 2012 seventh China grid annual conference. Rosten: IEEE, 2012: 68-75.
XIAO Y, LU L Y, LIU J S,et al. Knowledge diffusion path analysis of data quality literature: a main path analysis[J]. Journal of informetrics.2014:8(3), 594-605.
Yang G C, Li G, Li C Y, et al. Using the comprehensive patent citation network (CPC) to evaluate patent value[J]. Scientometrics, 2015, 105(3): 1319-1346.
YANG S Y, SOO V W. Extract conceptual graphs from plain texts in patent claims [J]. Engineering applications of artificial intelligence, 2012, 25(4): 874-887.
YOON B, PARK Y. A text-mining-based patent network: analytical tool for high-technology trend[J]. The journal of high technology management research, 2004, 15(1): 37-50.
YOON J, KIM K. An analysis of property–function based patent networks for strategic R&D planning in fast-moving industries: the case of silicon-based thin film solar cells[J]. Expert systems with applications, 2012, 39(9):7709-7717.
YOON J, KIM K. Trend perceptor: a property-function based technology intelligence system for identifying technology trends from patents[J].Expert system with application, 2012, 39(3):2927-2938.
[55]YOON J, KO N, KIM J. A function-based knowledge base for technology intelligence[J].Industrial engineering & management systems. 2015, 14(1):73-87.
YOUNG G, JONG H, SANG C. Visualization of patent analysis for emerging technology[J]. Expert systems with applications, 2008, 34(3): 1804-1812.
[143]
ZHA X, CHEN M. Study on early warning of competitive technical intelligence based on the patent map[J]. Journal of computers, 2010, 5(2): 274-281.
ZHAI Z, NGUYEN D Q, AKHONDI S A, et al. Improving chemical named entity recognition in patents with contextualized word embeddings[J]. arXiv preprint arXiv:1907.02679, 2019.
ZHANG L, LI L, LI T. Patent mining: a survey[J]. ACM sigkdd explorations newsletter, 2015, 16(2): 1-19.
ZHU J, KAPLAN R, JOHNSON J, et al. HiDDeN: hiding data with deep networks[J]. arXiv preprint arXiv: 1807.09937, 2018.
北京大学开放研究数据平台.发明专利数据[EB/OL].[2023-11-28]. https://opendata.pku.edu.cn/dataset.xhtml?persistentId=doi:10.18170/DVN/ASRTHL.(Peking University open research data. Invention patent data[EB/OL].[2023-11-28]. https://opendata.pku.edu.cn/dataset.xhtml?persistentId=doi:10.18170/DVN/ASRTHL.)
蔡莉, 王淑婷, 刘俊晖, 等. 数据标注研究综述[J]. 软件学报, 2020, 31(2): 302-320.(CAI L, WANG S T, LIU J H, et al. Survey of data annotation[J]. Journal of software, 2020, 31(2): 302-320.)
陈亮, 杨冠灿, 张静,等. 面向技术演化分析的多主路径方法研究[J]. 图书情报工作, 2015(10):115, 124-130.(CHEN L, YANG G C, ZHANG J, et al. Research on multiple main paths method oriented to analysis of technological evolution[J].Library and information service, 2015(10):115, 124-130.)
陈亮,张吉玉,刘一畅, 等.[三等奖方案]小样本数据分类任务赛题[复兴15号]团队解题思路. [EB/OL].[2023-08-26].https://mp.weixin.qq.com/s/dPWnm4OkxQLhAc-2uqSSUQ(CHEN L, ZHANG J Y, LIU Y C, et al. [Third Prize] Small sample data classification task [Fuxing No.15] Team problem solving ideas. [EB/OL].[2023-11-26].https://mp.weixin.qq.com/s/dPWnm4OkxQLhAc-2uqSSUQ.)
陈燕, 黄迎燕, 方建国. 专利信息采集与分析 [M]. 北京: 清华大学出版社, 2006.(CHEN Y, HUANG Y, FANG J G. Patent information collection and analysis[M]. Beijing: Tsinghua Press, 2006.)
方曙,胡正银,庞弘燊,等.基于专利文献的技术演化分析方法研究[J].图书情报工作, 2011, 55(22): 42-46.(FANG S, HU Z, PANG H, et al. Study on the method of analyzing technology evolution based on patent documents[J].Library and information service, 2011, 55(22): 42-46.)
费一楠, 张钊. 高级专利加工服务PATExpert简析[J]. 中国发明与专利, 2013(6): 54-57.(FEI Y N, ZHANG Z. The analysis of PATExpert for advanced patent processing service[J]). China invention& patent, 2013(6): 54-57.)
苟妍. 利用元路径提升的专利无效对比文件判断方法研究 [D].北京: 中国科学技术信息研究所, 2020. (GOU Y. Research on promotion methods of judging relevant patents in patent invalidation cases based on meta-path feature [D]. Beijing: Institute of Scientific and Technical Information of China, 2020.)
胡正银,方曙. 专利文本技术挖掘研究进展综述[J]. 现代图书情报技术,2014,30(6):62-70.(HU Z Y, FANG S. Review on text-based patent technology mining[J]. New technology of library and information service, 2014,30(6):62-70.)
黄鲁成,李欣,吴菲菲.技术未来分析理论方法与应用[M].北京:科学出版社,2010.(HUANG L C, LI X, WU F F. Theoretical method and application of technology future analysis[M]. Beijing: Science Press,2010.)
李金鹏, 张闯,陈小军,等. 自动文本摘要研究综述[J]. 计算机研究与发展, 2021, 58(1): 1-21.(LI J P, ZHANG C, CHEN X J, et al. Survey on automatic text summarization[J]. Journal of computer research and development, 2021, 58(1): 1-21.)
吕璐成,韩涛,周健,等. 基于深度学习的中文专利自动分类方法研究[J]. 图书情报工作,2020,64(10):75-85.(Lv L C, HAN T, ZHOU J, et al. Research on the method of Chinese patent automatic classification based on deep learning[J].Library and information service, 2020,64(10):75-85.)
马天旗, 赵强, 苏丹, 等. 专利挖掘(第2版)[M].北京:知识产权出版社, 2020.(MA T, ZHAO Q, SU D, et al. Patent mining(2nd edition)[M]. Beijing: Intellectual Property Publishing Hourse,2020.)
屈鹏,张均胜,曾文,等. 国内外专利挖掘研究(2005-2014)综述[J]. 图书情报工作, 2014, 58(20) : 131-137.(QU P, ZHANG J S, ZENG W, et al. A review of patent mining studies in China and abroad 2005-2014[J]. Library and information service, 2014, 58(20) : 131-137. )
沈萌红.创新的方法-TRIZ理论概述[M].北京:北京大学出版社,2011.(SHEN M H. Innovative methods: an overview of TRIZ theory[M]. Beijing: Peking University Press, 2011.)
师英昭. 利用图嵌入特征强化的专利对比文件检索方法研究 [D].北京: 中国科学技术信息研究所, 2021.(SHI Y Z. Research on the retrieval method of patent comparative document using graph embedding feature enhancement[D].Beijing: Institute of Scientific and Technical Information of China, 2021.)
王亮,张绍武,丁堃,等.基于HDP的汽车专利主题演化研究[J].情报学报, 2015, 33(9): 944-951.(WANG L, ZHANG S W, DING K, et al. HDP-based vehicle patent topic evolution[J]. Journal of the China society for scientific and technical information, 2015, 33(9): 944-951.)
肖国华,郭捷婷.专利分析方法研究[J].情报杂志,2008 (1):12-15.(XIAO G H, GUO J T. The study of patent information analysis[J]. Journal of intelligence, 2008(1):12-15.)
[68]薛驰, 邱清盈, 冯培恩,等. 机械产品专利作用结构知识提取方法研究[J]. 农业机械学报, 2013, 44(1):222-229.(XUE C, QIU Q, FENG P, et al. Acquisition method for principle solution of mechanical patent[J]. Transactions of the Chinese Society for Agricultural Machinery, 2013, 44(1):222-229)
张雪, 孙宏宇, 辛东兴,等. 自动术语抽取研究综述. 软件学报,2020, 31(7): 2062-2094.(ZHANG X, SUN H Y, XIN D X, et al. Survey on Automatic Term Extraction Research. Journal of software, 2020, 31(7): 2062-2094)
中华人民共和国知识产权局. 专利审查指南(2010)[M].北京: 知识产权出版社, 2009. (CHINA NATIONAL INTELLECTUAL PROPERTY ADMINISTRATION. Patent examination guideline[M]. Beijing: Intellectual Property Publishing House, 2009 )
